📝 Paper Summary
LLM Recommendation
Machine Unlearning
E2URec enables efficient removal of specific user data from LLM-based recommenders by updating only lightweight LoRA adapters guided by forgetting and remembering teachers.
Core Problem
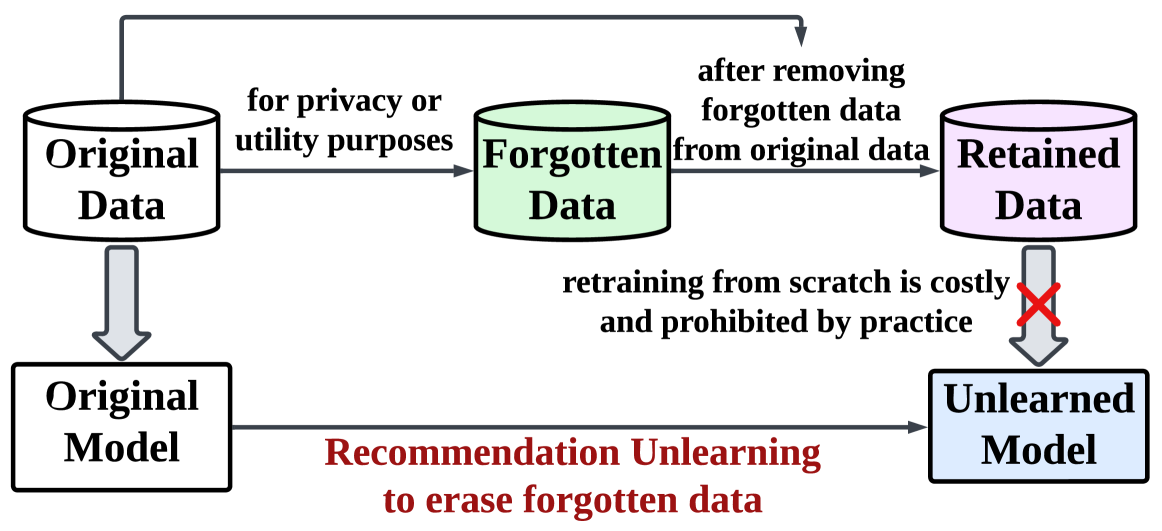
Existing unlearning methods for recommenders are either computationally prohibitive for LLMs (requiring full retraining or Hessian computation) or degrade model utility on remaining data (using gradient ascent).
Why it matters:
- Privacy regulations like GDPR and CCPA require recommenders to delete sensitive user data upon request, which is difficult for large pre-trained models
- Noisy or polluted data degrades recommendation performance, necessitating targeted removal to regain utility
- Retraining billion-parameter LLMs from scratch for every deletion request is computationally infeasible
Concrete Example:
If a user requests deletion of their interaction history due to privacy concerns, standard methods might require re-tuning the entire LLM (costly) or simply inverting the gradient (damaging general recommendation ability).
Key Novelty
E2URec (Efficient and Effective Unlearning for LLMRec)
- Decouples unlearning from the massive LLM backbone by inserting and updating only lightweight LoRA (Low-Rank Adaptation) modules, freezing the main model
- Uses a 'forgetting teacher' (simulated by subtracting augmented model logits from original logits) to guide the model away from forgotten data
- Uses a 'remembering teacher' (the original model) to constrain the unlearned model, ensuring it maintains high performance on retained data
Architecture
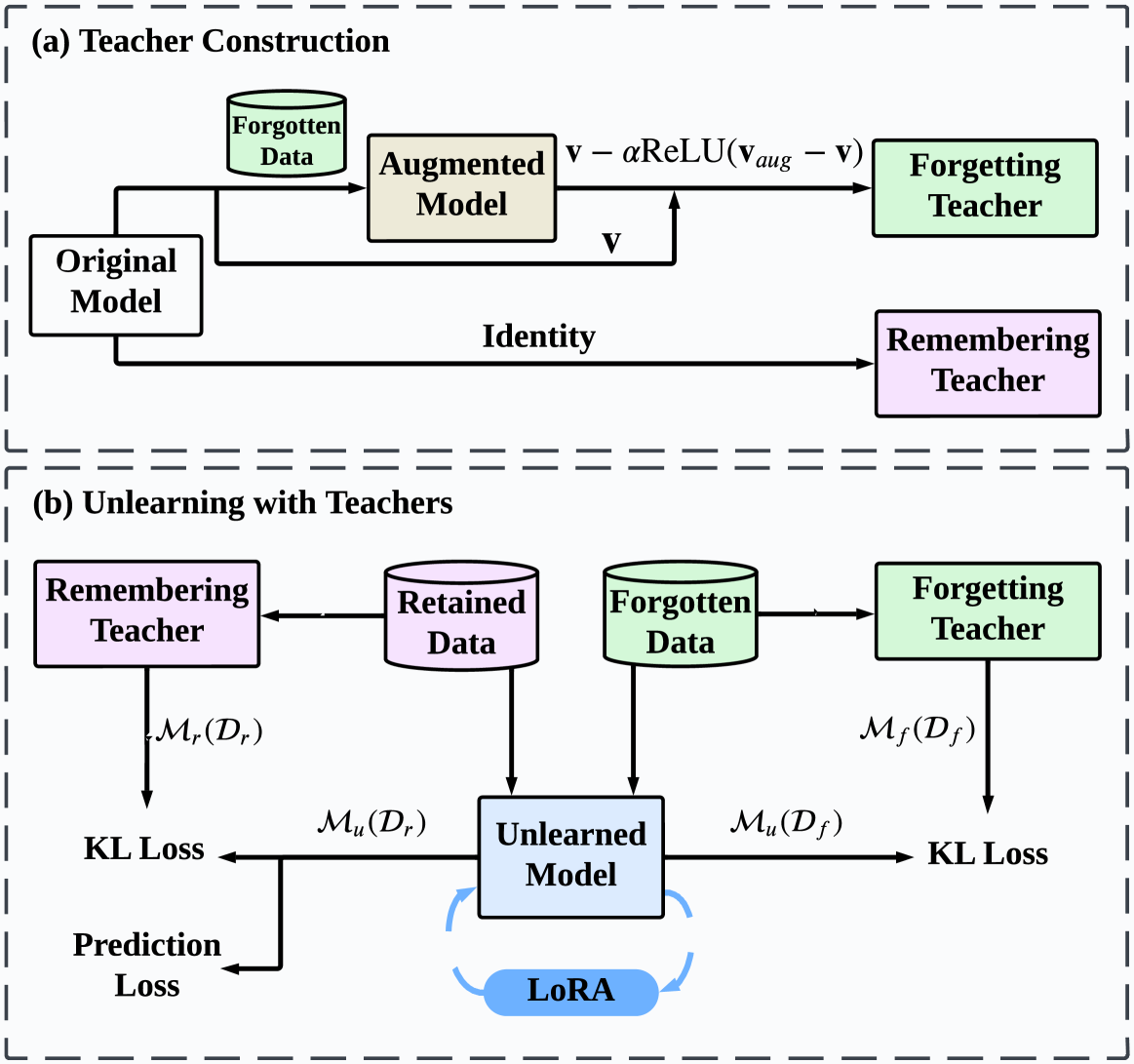
The overall framework of E2URec, illustrating the construction of the forgetting teacher and the LoRA-based unlearning process.
Evaluation Highlights
- Achieved unlearning efficacy comparable to Retrain (the gold standard) while being significantly faster, with near-zero performance drop on retained data
- Outperformed gradient ascent-based baselines (GA, GA+KL) which suffered severe utility degradation (e.g., AUC drops of >10%)
- Demonstrated efficiency by updating only a small fraction of parameters compared to full fine-tuning methods
Breakthrough Assessment
7/10
First specialized unlearning method for LLM-based recommendation. cleverly combines efficient tuning (LoRA) with a dual-teacher distillation approach to solve the specific stability-plasticity dilemma in unlearning.