📝 Paper Summary
Content-based Recommendation
LLM for Recommendation
ONCE synergizes open-source LLMs as fine-tunable content encoders and closed-source LLMs as data augmenters to achieve state-of-the-art performance in content-based recommendation.
Core Problem
Existing content encoders (CNNs, BERT) struggle with deep semantic understanding and lack external knowledge, leading to inaccurate similarity measurements between items with superficial textual overlaps.
Why it matters:
- Traditional encoders relying on word overlap fail to distinguish distinct concepts (e.g., 'The Lion King' vs. 'The Lions of Al-Rassan'), hurting recommendation accuracy.
- Small PLMs (Pretrained Language Models) like BERT lack the world knowledge and capacity to model complex user interests effectively.
- Directly using closed-source LLMs as recommenders (via prompting) often underperforms specialized models due to high latency and lack of collaborative signal integration.
Concrete Example:
When encoding book titles, traditional models judge 'The Lion King' (Disney movie) and 'The Lions of Al-Rassan' (historical fantasy) as highly similar due to the word 'Lion'. LLaMA, possessing rich world knowledge, correctly encodes their distinct genres, placing 'The Lions of Al-Rassan' closer to 'The Summer Tree' (another fantasy novel) despite less lexical overlap.
Key Novelty
ONCE Framework (Open- and Closed-source LLMs)
- DIRE (Discriminative Recommendation): Replaces traditional content encoders with open-source LLMs (LLaMA), freezing lower layers and fine-tuning top layers to create dense content embeddings.
- GENRE (Generative Recommendation): Uses closed-source LLMs (GPT-3.5) to synthesize rich training data (summaries, inferred user profiles, synthetic history) to overcome data sparsity and enrich semantics.
- Synergy: Data generated by GENRE accelerates the training convergence of DIRE and improves its final recommendation performance.
Architecture
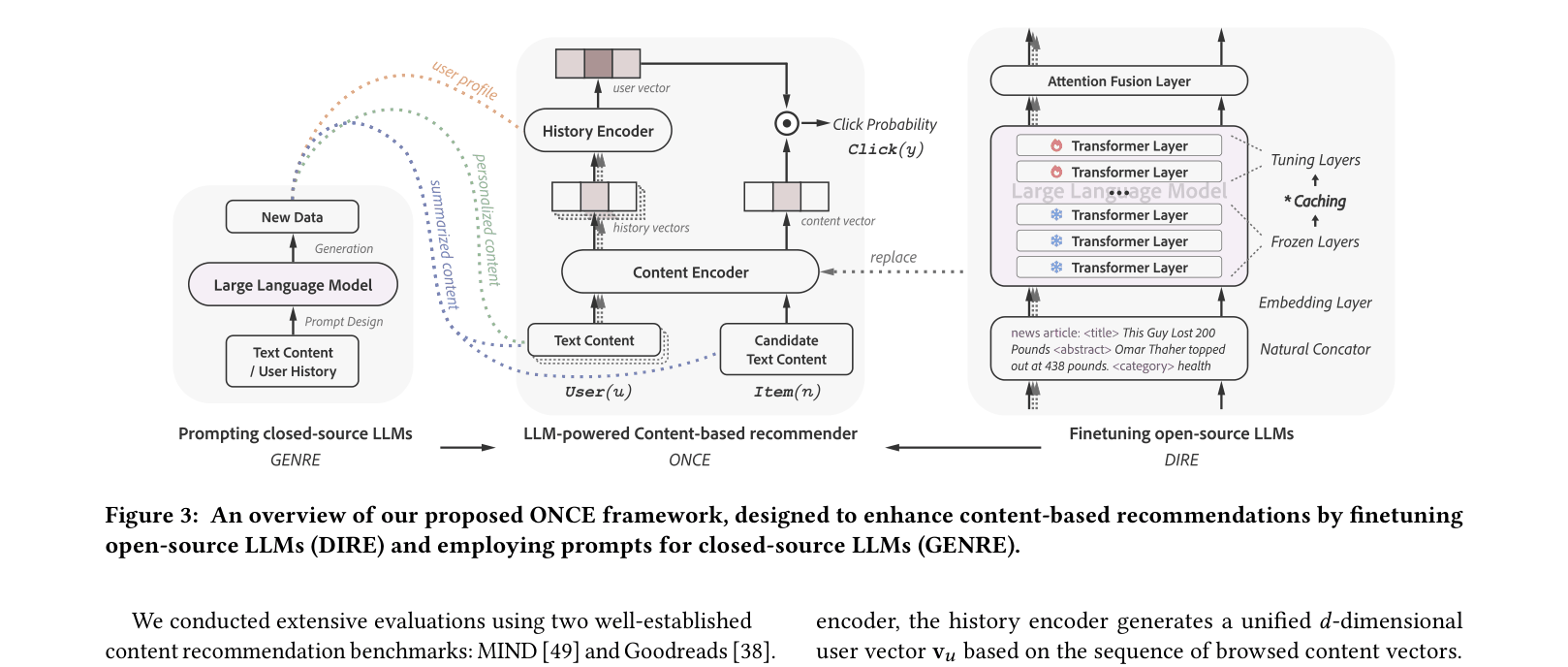
Overview of the ONCE framework pipeline integrating DIRE and GENRE components.
Evaluation Highlights
- Achieves up to +19.32% relative improvement over state-of-the-art BERT-based baselines on MIND news recommendation.
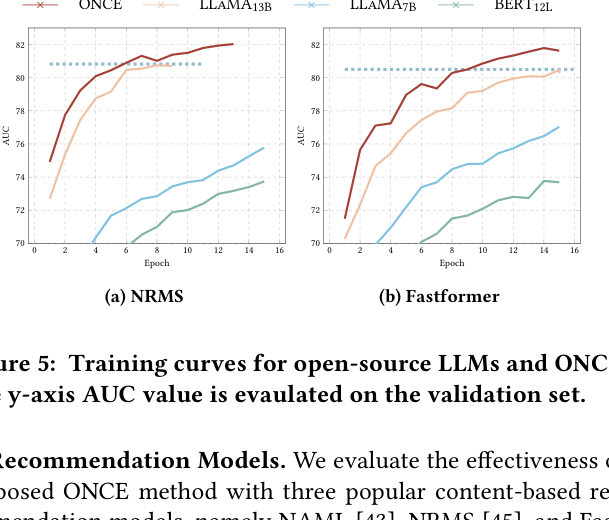
- ONCE (LLaMA-13B) reaches the performance of a standard LLaMA-13B model's 8th epoch in just 6 epochs (+25% training speed) when using GPT-generated data.
- Consistently outperforms baselines on Goodreads book recommendation, boosting nDCG@1 by over 5 points compared to BERT-12L.
Breakthrough Assessment
8/10
Significantly advances content-based recommendation by successfully integrating LLMs into the pipeline in two distinct, complementary roles (encoder vs. augmenter), yielding substantial empirical gains.