📝 Paper Summary
Conversational Recommendation Systems
Multimodal Large Language Models
ILM bridges the gap between collaborative filtering signals and language models by using a Q-Former to translate item embeddings into text-aligned representations that a frozen LLM can understand.
Core Problem
LLMs lack native understanding of collaborative filtering signals (like co-watch history) crucial for recommendation, and existing text-only prompts or simple linear projections fail to capture these complex patterns effectively.
Why it matters:
- User interactions (clicks, views) are the strongest signals for recommendation but are not natural language, making them hard for standard LLMs to utilize.
- Fine-tuning LLMs on interaction data risks catastrophic forgetting of their reasoning abilities and raises privacy concerns.
- Simple projection methods (like MLPs) leave a modality gap between collaborative embeddings and the LLM's token space, requiring expensive full-model fine-tuning.
Concrete Example:
If Users A and B both watched Video 1 and Video 2, a collaborative filtering model knows Video 2 is a good candidate for User A. However, an LLM prompted only with text descriptions might not see the connection if the videos have dissimilar titles or descriptions. ILM encodes this co-watch signal directly into a representation the LLM can process.
Key Novelty
Item-Language Model (ILM) with Contrastive Q-Former
- Adapts the BLIP-2 architecture to recommendation by treating items as a 'modality' analogous to images, using a Q-Former to map collaborative filtering embeddings into the LLM's input space.
- Introduces a novel item-item contrastive loss during pre-training, which forces the item encoder to learn co-occurrence patterns (interaction signals) alongside standard item-text alignment.
- Keeps the massive LLM backbone frozen during all training phases, updating only the lightweight adapter, preserving the LLM's original reasoning and language capabilities.
Architecture
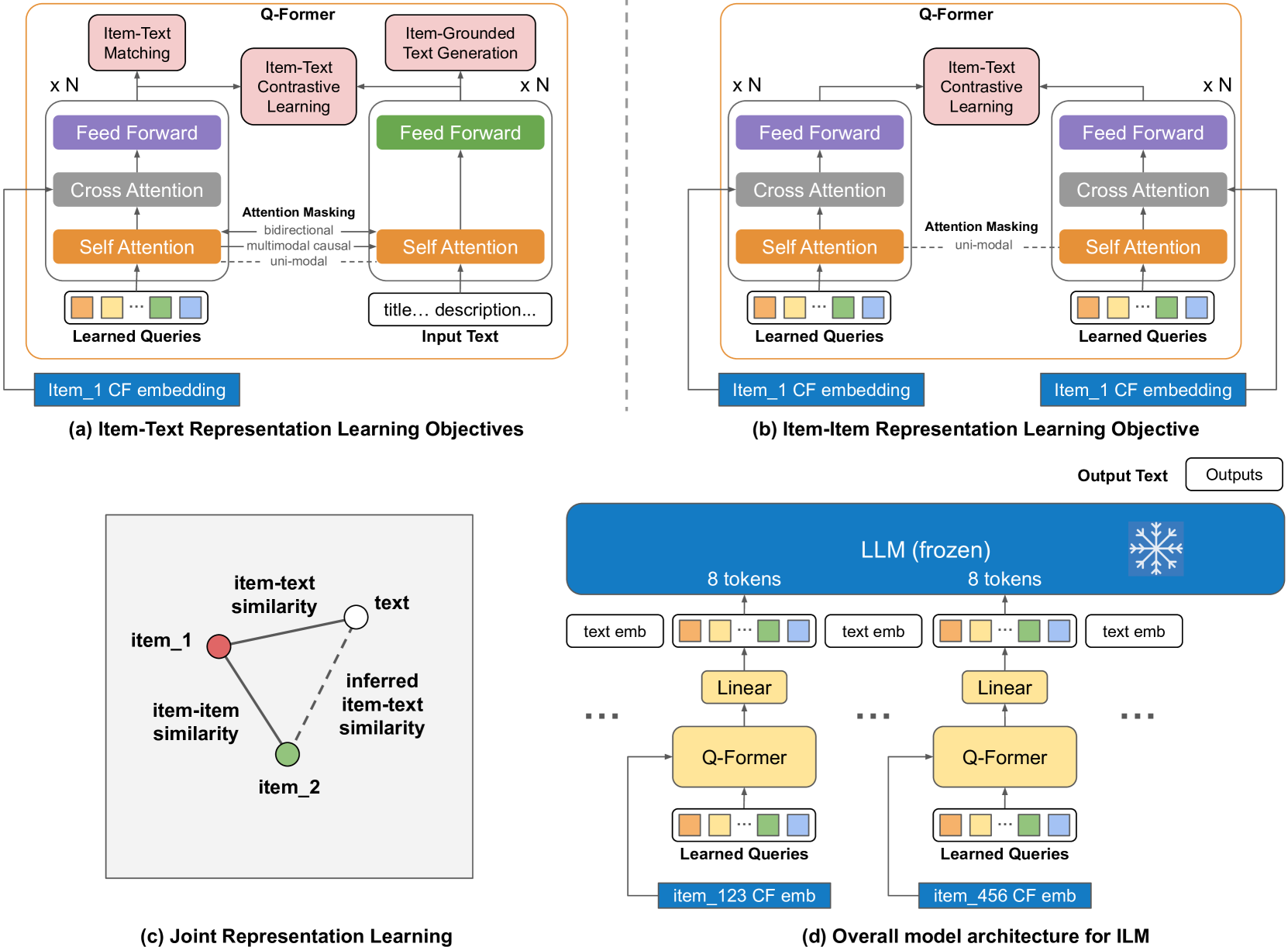
The training pipeline of ILM, including the contrastive pre-training phases and the final integration with the LLM.
Evaluation Highlights
- Outperforms MLP-based baselines (CoLLM) on all 24 ELM tasks (user preference elicitation, explanation, etc.), showing better alignment of interaction signals.
- Achieves higher Hit Rate and NDCG on OpenP5 benchmarks (MovieLens-1M, Beauty, Clothing) compared to random indexing and MLP baselines.
- Ablation studies confirm the item-item contrastive loss specifically improves performance by encoding collaborative signals that text alignment alone misses.
Breakthrough Assessment
7/10
A strong methodological contribution applying vision-language alignment techniques (BLIP-2) to recommendation. It elegantly solves the modality gap between IDs and text without retraining the LLM, though it relies on existing architectures.