📝 Paper Summary
News Recommendation
LLM Data Augmentation
This paper enhances neural news recommendation models by using an LLM to generate detailed textual descriptions for news categories, which are then concatenated with article titles during training and inference.
Core Problem
Standard news recommendation models typically use news categories via generic templates (e.g., 'The news category is {category}'), which fail to capture the semantic richness and specific context of diverse topics.
Why it matters:
- Pre-trained language models (PLMs) used in news encoders often lack the specific knowledge to interpret obscure or domain-specific category names (e.g., 'tv-golden-globes') without context.
- Manual creation of detailed descriptions for hundreds of news categories is costly and unscalable.
- Insufficient category representation limits the ability of recommendation models to accurately match user interests with news content.
Concrete Example:
For the category 'tv-golden-globes', a standard model might just see the string or a template 'The news category is tv-golden-globes'. This misses context about the 'television industry', 'nominations', and 'awards', which are explicit in the LLM-generated description.
Key Novelty
LLM-Augmented Category Descriptions
- Leverage an LLM (GPT-4) to automatically generate informative, paragraph-length descriptions for all news categories in the dataset.
- Integrate these descriptions into existing neural news recommendation architectures by concatenating them with the news title before feeding into the news encoder.
Architecture
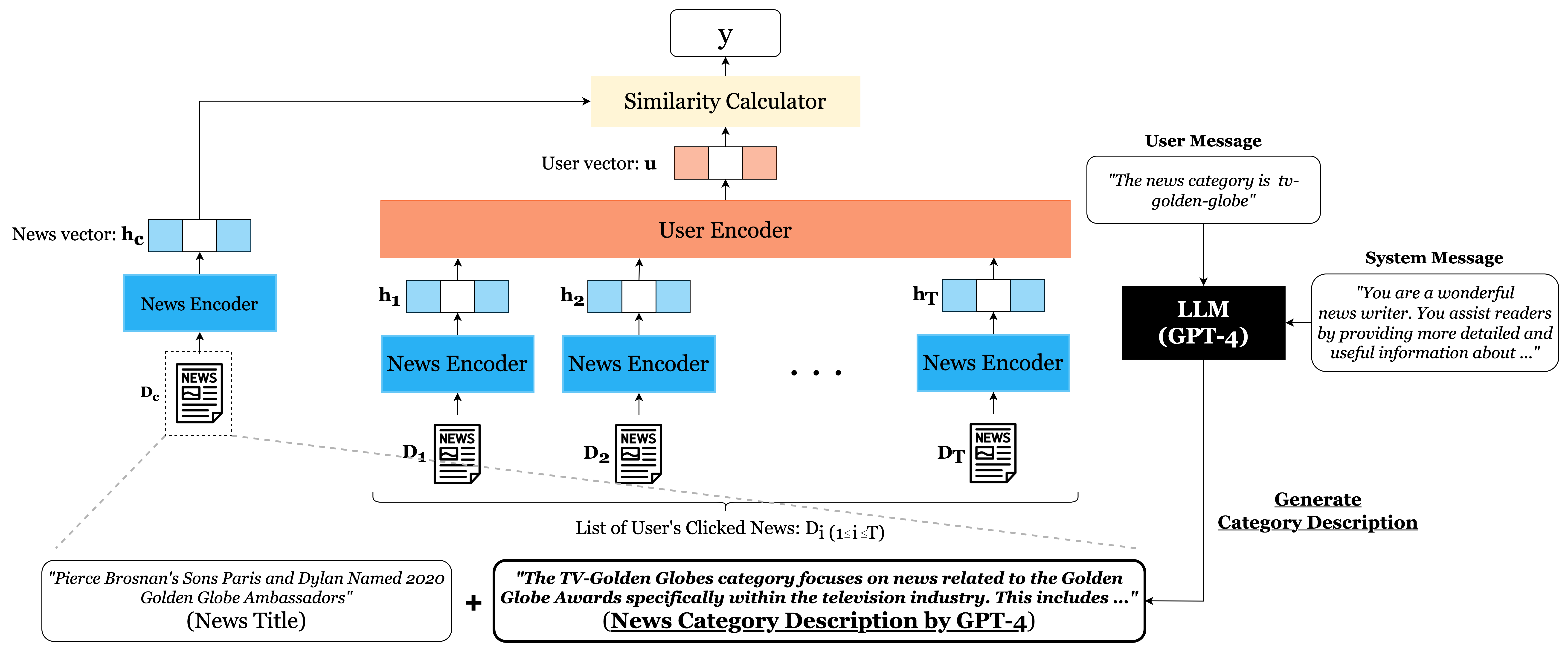
The workflow of the proposed method, illustrating the generation of descriptions and their integration into the news encoder.
Evaluation Highlights
- Achieved up to 5.8% improvement in AUC compared to template-based baselines when applied to state-of-the-art models (NAML, NRMS, NPA).
- Consistently outperformed 'title only' and 'title + template-based' baselines across multiple metrics (AUC, MRR, nDCG) on the MIND dataset.
- Demonstrated effectiveness across different PLM backbones (BERT-base, DistilBERT-base).
Breakthrough Assessment
4/10
A straightforward but effective application of LLMs for data augmentation in recommender systems. While not architecturally novel, it provides a practical method for enriching semantic features.