📝 Paper Summary
Sequential Recommendation
Cross-domain Recommendation
LLM for Recommendation
LLM-Rec leverages the world knowledge and semantic understanding of pre-trained Large Language Models to unify user behaviors across multiple domains into a single sequence, addressing data sparsity and cold-start problems without complex domain-specific architectures.
Core Problem
Traditional multi-domain recommendation systems struggle with data sparsity and cold-start issues because they rely on ID-based representations that lack semantic meaning and fail to align items across domains.
Why it matters:
- Current cross-domain methods require complex, rigid architectures (e.g., pair-wise links) that scale poorly to many domains
- ID-based methods cannot transfer semantic knowledge; a user's interest in 'running shoes' in one domain doesn't naturally map to 'sports drinks' in another without explicit overlap
- Existing sequential models often fail to capture long-term dependencies or semantic correlations between diverse user interests
Concrete Example:
In a preliminary study, simply concatenating item IDs from five different domains and feeding them into SASRec resulted in performance degradation compared to single-domain models, proving that ID-based methods fail to capture cross-domain semantic connections.
Key Novelty
LLM-Rec: Domain-Agnostic LLM Framework
- Treats multi-domain recommendation as a text-to-text problem by converting item titles into text and concatenating them into a single user history sentence
- Uses a single pre-trained LLM backbone to encode both user history and candidate items, relying on the LLM's internal 'world knowledge' to bridge semantic gaps between domains
- Demonstrates that larger model sizes (scaling laws) and instruction tuning (LoRA) significantly benefit recommendation performance, unlike traditional ID-based models
Architecture
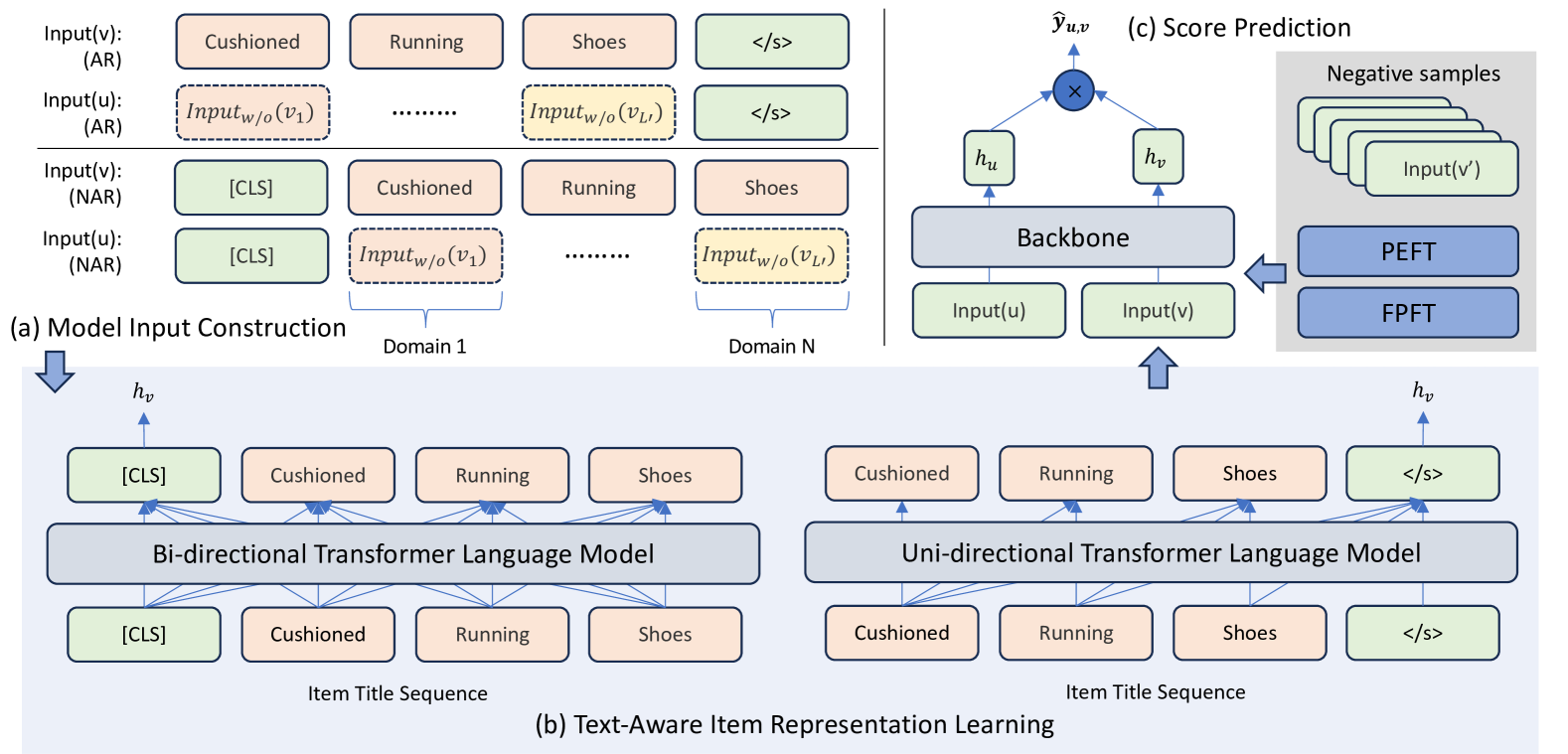
The overall framework of LLM-Rec, illustrating how user behaviors from different domains are concatenated into a text sequence, processed by various LLM backbones (Encoder-only, Decoder-only, Encoder-Decoder), and used for next-item prediction.
Evaluation Highlights
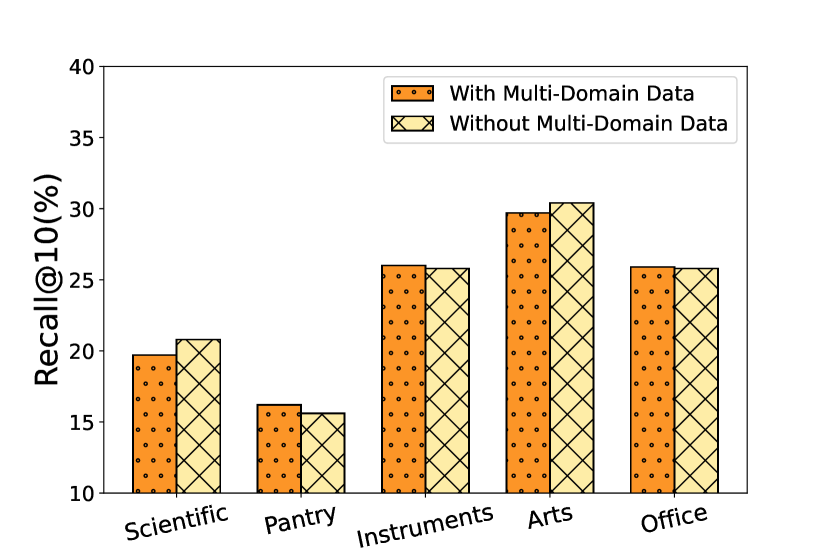
- Outperforms state-of-the-art baselines like SASRec and UniSRec on 5 diverse datasets, with gains particularly strong in sparse/cold-start scenarios
- Larger models yield better performance: scaling from 125M to 6.7B parameters consistently improves recommendation accuracy, confirming NLP scaling laws apply here
- Fine-tuning with LoRA achieves comparable or better results than full parameter tuning while requiring significantly fewer trainable parameters
Breakthrough Assessment
7/10
Strong empirical validation of LLMs for multi-domain recommendation without complex graph/task structures. Successfully applies NLP scaling laws to RecSys, though the architectural innovation is primarily the application of existing LLMs to a new setting.