📝 Paper Summary
Sequential Recommendation
Graph-based Recommendation
LLM for Recommendation
LLMRG utilizes Large Language Models to dynamically construct and verify personalized reasoning graphs that capture causal relationships in user behavior, which are then encoded and fused with traditional sequential recommendation models.
Core Problem
Conventional recommender systems rely on statistical patterns in interaction sequences without understanding the semantic or causal reasoning behind user behaviors, while existing knowledge graph approaches are static and lack complex reasoning capabilities.
Why it matters:
- Current systems struggle to capture higher-level semantic relationships between user interests and behaviors, limiting recommendation quality.
- Lack of interpretability makes it difficult to understand the 'why' behind specific user choices.
- Static knowledge graphs require extensive human expertise and often suffer from coverage gaps or inability to reason about latent relationships.
Concrete Example:
If a user watches a sci-fi movie, a traditional model might just recommend another popular sci-fi film. LLMRG reasons that the user is interested in 'sci-fi with complex philosophies,' and proactively generates a chain leading to cerebral sci-fi films with similar themes, even if they aren't the immediate statistical neighbors.
Key Novelty
Large Language Model Reasoning Graphs (LLMRG)
- Uses LLMs to generate 'reasoning chains' linking user history to potential future items based on causal/logical inference, rather than just static facts.
- Introduces a 'divergent extension' module where the LLM uses 'imagination' to predict proactive future interests beyond the immediate history.
- Implements a self-verification mechanism using abductive reasoning (masking and predicting) to score and filter the quality of generated reasoning chains.
Architecture
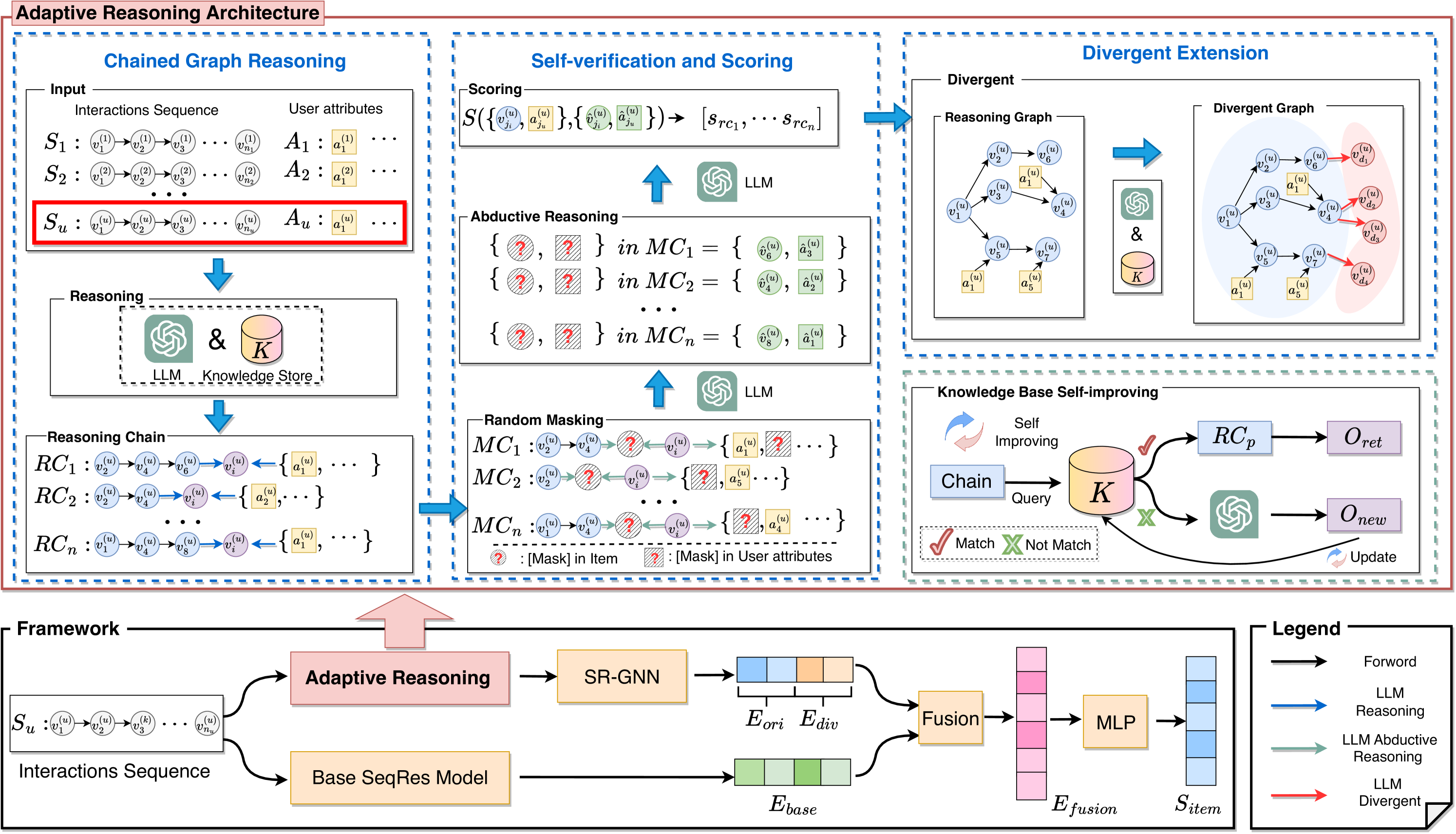
The overall architecture of LLMRG, illustrating the Adaptive Reasoning Module (Chain Reasoning, Verification, Divergent Extension) and its fusion with a Base Sequential Recommendation Model.
Evaluation Highlights
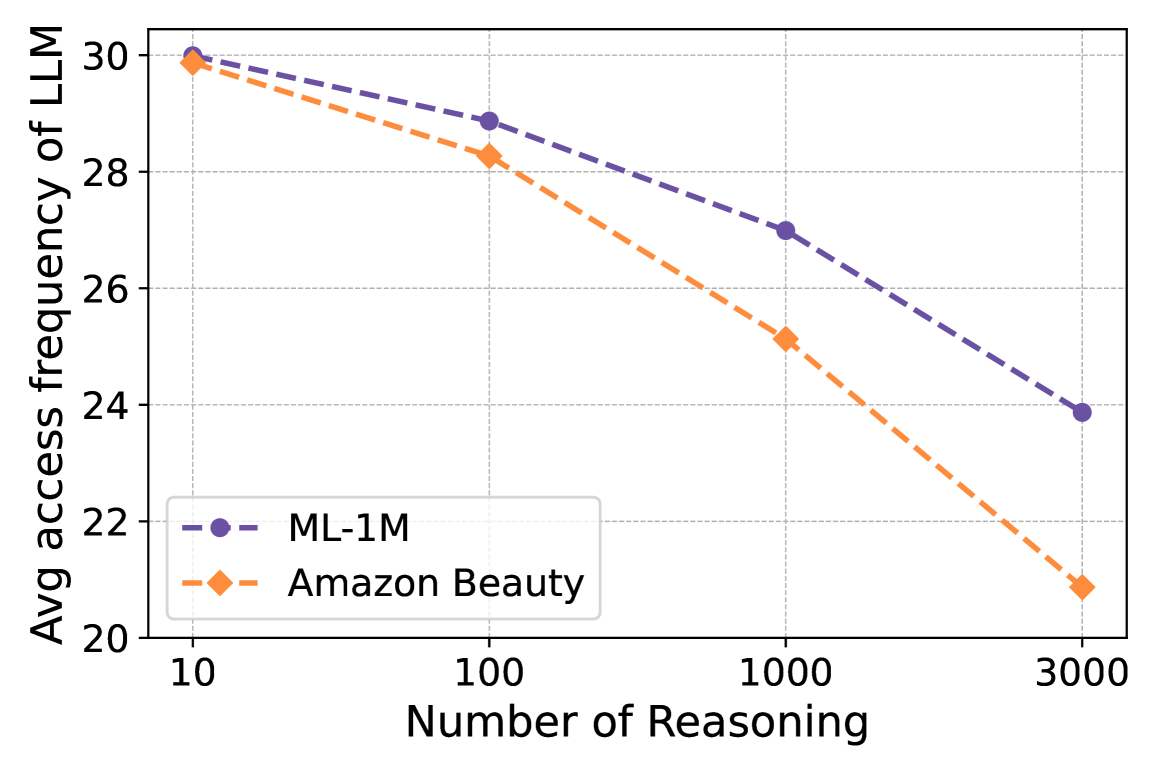
- Reduces language model usage by about 30% compared to inference from scratch after 3000 reasoning steps via the self-improving knowledge base.
- Improves performance of base sequential recommendation models (BERT4Rec, FDSA, CL4SRec, DuoRec) by fusing reasoning graph embeddings [Specific accuracy deltas not present in text].
- Demonstrates capability to interpret recommendations by surfacing explicit reasoning chains constructed by the LLM.
Breakthrough Assessment
8/10
Novel integration of LLM-based causal reasoning directly into graph structures for recommendation, addressing the semantic gap in traditional sequential models. The self-verification and caching mechanisms address key practical hurdles (hallucination and cost).