📝 Paper Summary
Conversational Recommender Systems (CRS)
Synthetic Data Generation
Pearl is a large-scale synthetic conversational recommendation dataset generated by LLM simulators that leverage real-world user reviews to ensure specific user personas and detailed item knowledge.
Core Problem
Existing CRS datasets (collected via crowdsourcing) suffer from generic user preferences and uninformative recommendations because crowdworkers lack real intent and domain knowledge.
Why it matters:
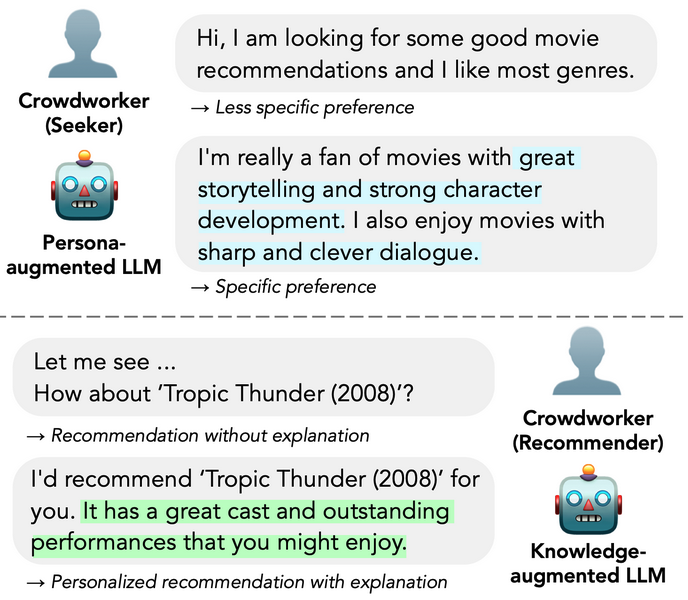
- Crowdworkers often roleplay with vague prompts like 'I like most genres,' leading to generic models that fail to personalize recommendations.
- Recommender responses in current datasets often lack explanations (e.g., just listing a title), preventing users from understanding why an item fits their needs.
- The lack of specificity and reasoning in training data fundamentally limits the quality of downstream conversational agents.
Concrete Example:
In existing datasets like ReDial, a user might say 'I like most genres,' and a recommender might reply 'How about Tropic Thunder?' without explanation. In Pearl, a simulated user based on real reviews expresses specific tastes (e.g., 'I dislike horror but love 80s sci-fi'), and the recommender explains *why* a movie fits those constraints.
Key Novelty
Review-Driven Multi-Agent Simulation
- Constructs a 'User Simulator' grounded in a persona derived from a specific real-world user's review history (IMDB), ensuring consistent and specific preferences.
- Constructs a 'Recommender Simulator' grounded in item-review knowledge, allowing it to provide reasoning based on 'soft attributes' (e.g., 'feel-good movie') found in reviews rather than just metadata.
- Filters synthetic dialogues using Natural Language Inference (NLI) to ensure the generated conversation strictly adheres to the assigned persona and item facts.
Architecture
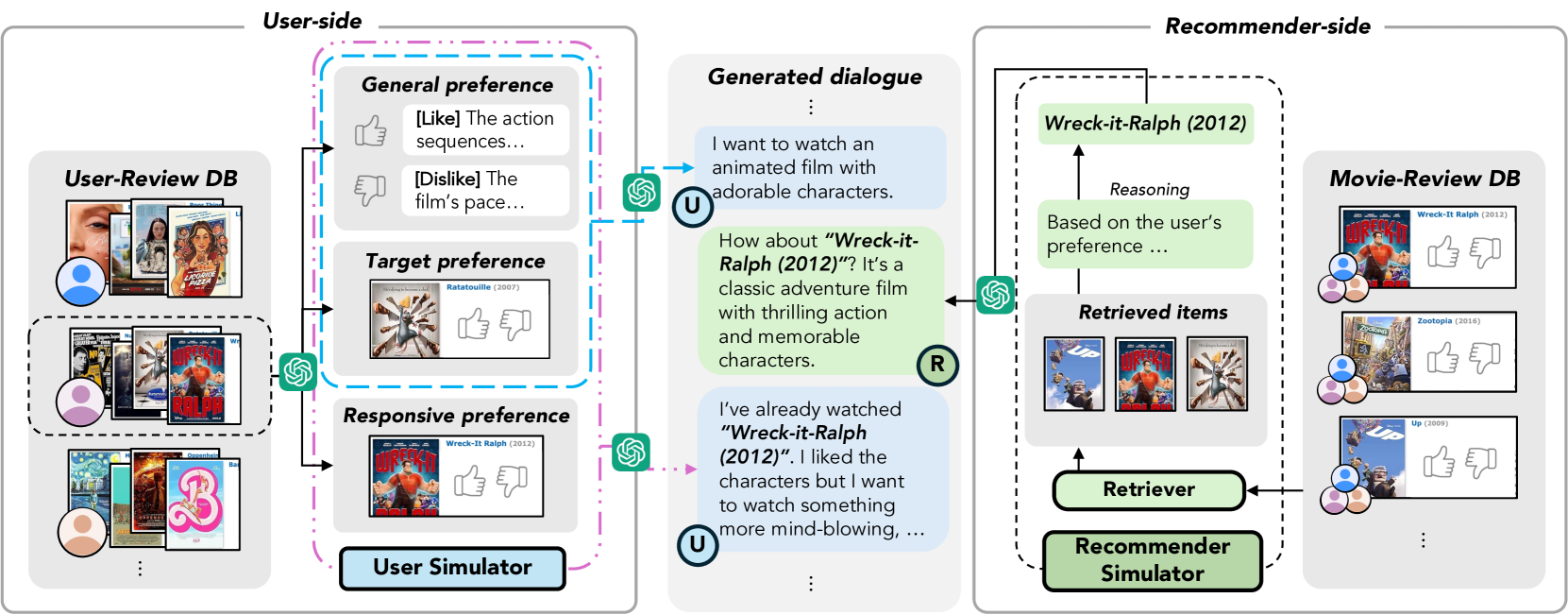
The data construction pipeline for Pearl. It illustrates the interaction between the User Simulator (left) and Recommender Simulator (right).
Evaluation Highlights
- Pearl-trained models achieve higher human preference scores (Win/Tie/Loss) against ReDial-trained models, with judges preferring Pearl responses 56.7% of the time vs 26.7% for ReDial.
- On the recommendation task (Hit@1), a model trained on Pearl (KBRD) achieves 6.94% compared to 3.56% when trained on ReDial.
- Demonstrates better generalization: Models trained on Pearl perform significantly better when tested on unseen datasets (OpenDialKG) compared to models trained on other baselines.
Breakthrough Assessment
8/10
Significantly improves the quality of CRS training data by moving away from low-effort crowdsourcing to rigorous, review-grounded synthesis. The scale (57k dialogues) and detail address a major bottleneck in the field.