📝 Paper Summary
Explainable Recommendation
LLM-based Recommendation
XRec integrates collaborative filtering signals into large language models via a mixture-of-experts adapter and multi-layer embedding injection to generate personalized explanations for user-item interactions.
Core Problem
Collaborative filtering models are accurate but act as black boxes, while existing explanation methods lack the data efficiency and generalization capabilities to justify recommendations effectively.
Why it matters:
- Users need transparency to trust recommender systems and understand why specific items are shown to them
- Existing ID-based explanation methods struggle with zero-shot scenarios and unseen users/items due to reliance on specific ID embeddings
- Standard LLMs lack specific knowledge of collaborative user preferences and interaction patterns inherent in recommendation data
Concrete Example:
A standard collaborative filtering model might accurately recommend a restaurant based on purchase history but cannot explain *why* (e.g., 'because you like spicy food and casual dining'). An LLM might generate fluent text but hallucinate reasons unrelated to the user's actual behavior history.
Key Novelty
Deep Collaborative Instruction Tuning
- Treats a Graph Neural Network (LightGCN) as a 'tokenizer' that converts user interaction graphs into collaborative embeddings
- Bridges the gap between graph embeddings and LLM text space using a Mixture-of-Experts (MoE) adapter
- Injects these adapted collaborative tokens into *every* layer of the LLM (not just the input) to prevent the signal from being diluted during long-text generation
Architecture
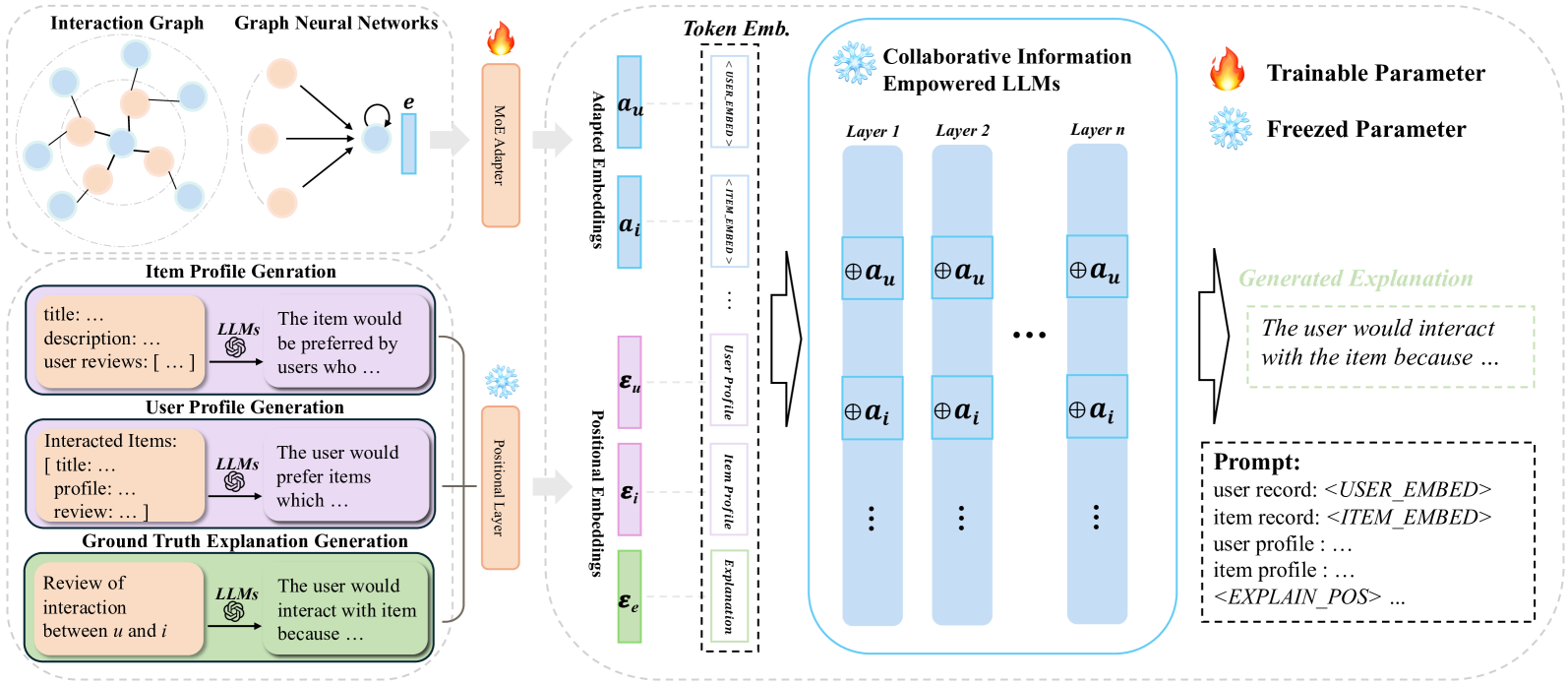
The XRec framework pipeline: (1) Interaction Graph, (2) LightGCN Tokenizer, (3) MoE Adapter, (4) LLM with Deep Injection.
Breakthrough Assessment
8/10
Proposes a novel architectural integration (layer-wise injection) to solve the 'signal dilution' problem in LLM-based recommendation, moving beyond simple prompt tuning.