📝 Paper Summary
Generative Recommendation
Reasoning in LLMs
OneRec-Think integrates explicit textual reasoning into generative recommendation via a unified LLM framework, using a novel beam-aware reward function to optimize for the multi-valid nature of user preferences.
Core Problem
Existing generative recommenders (like OneRec) operate as black-box implicit predictors lacking explicit reasoning, while current reasoning-based methods are often limited to reranking or lack scalability.
Why it matters:
- Implicit models cannot explain why an item was chosen, reducing user trust and interpretability
- Standard Chain-of-Thought methods fail in recommendation because user preferences are 'multi-valid' (many correct answers), causing sparse rewards during training
- Deploying heavy reasoning models in real-time industrial systems is computationally prohibitive due to latency constraints
Concrete Example:
A user who just watched several sad movies might want a comedy next to cheer up. A standard generative model might just predict another sad movie based on pattern matching. OneRec-Think generates a rationale: 'The user has watched intense dramas; to alleviate negative emotions, a relaxing comedy is appropriate,' and then predicts the comedy.
Key Novelty
Unified Generative Reasoning with Rollout-Beam Reward
- Interleaves 'itemic' tokens (representing items) with natural language text to perform reasoning and recommendation in a single autoregressive flow
- Introduces 'Rollout-Beam' reward for Reinforcement Learning, which credits a reasoning path if *any* item in the subsequent beam search matches the target, addressing reward sparsity
- Uses a 'Think-Ahead' inference architecture that pre-computes reasoning and initial tokens offline, allowing real-time completion online
Architecture
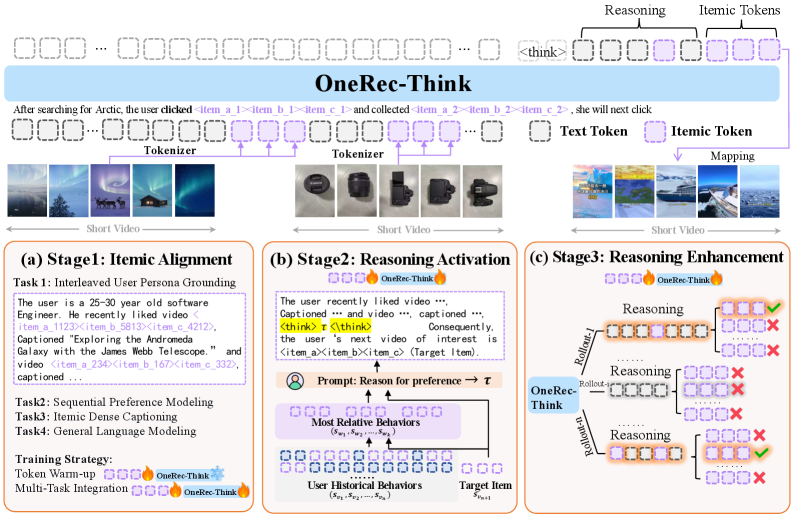
Overview of the OneRec-Think framework including Itemic Alignment, Reasoning Activation, and Reasoning Enhancement stages.
Evaluation Highlights
- Achieves state-of-the-art results on Amazon Beauty, Toys, and Sports datasets, outperforming both sequential (SASRec) and generative (ReaRec, TIGER) baselines
- In live industrial deployment on Kuaishou, increases APP Stay Time by 0.159% against a strong online baseline
- Ablation studies show that adding reasoning to the aligned base model improves Recall@5 by over 10% on the Beauty dataset
Breakthrough Assessment
8/10
Successfully bridges the gap between explicit LLM reasoning and industrial-scale generative recommendation with a practical solution for latency (Think-Ahead) and training stability (Rollout-Beam).

