📝 Paper Summary
LLM-based Recommendation
Efficient Inference
Speculative Decoding
AtSpeed accelerates LLM-based generative recommendation by adapting Speculative Decoding for strict N-to-K beam search verification and introducing a relaxed verification strategy to reduce trivial rejections.
Core Problem
Standard Speculative Decoding (SD) fails in generative recommendation because beam search requires verifying K distinct sequences simultaneously (N-to-K verification), making it much harder to accept drafted tokens than in standard 1-to-1 generation.
Why it matters:
- LLM-based recommendation is prohibitively slow due to autoregressive decoding of multiple items (beam search) in real-time
- Existing SD methods designed for single-sequence generation (N-to-1) in NLP are inefficient for recommendation tasks requiring top-K lists, leading to frequent rejections and wasted compute
Concrete Example:
In a recommendation scenario requiring Top-3 items, standard SD might draft 2 correct items but miss the 3rd. Under strict beam search rules, this entire step is rejected because the full Top-3 set wasn't found, wasting the draft computation. AtSpeed's relaxed verification allows accepting the valid items even if the set isn't a perfect match.
Key Novelty
Speculative Decoding for N-to-K Verification (AtSpeed)
- Formulates the first SD framework specifically for beam search in recommendation, shifting from N-to-1 to N-to-K verification
- Introduces 'AtSpeed-S' to align the draft model's top-K predictions with the target model using Reverse KL Divergence
- Proposes 'AtSpeed-R', a relaxed sampling verification that accepts high-probability non-top-K drafts if they align with the target's distribution, significantly boosting acceptance rates
Architecture
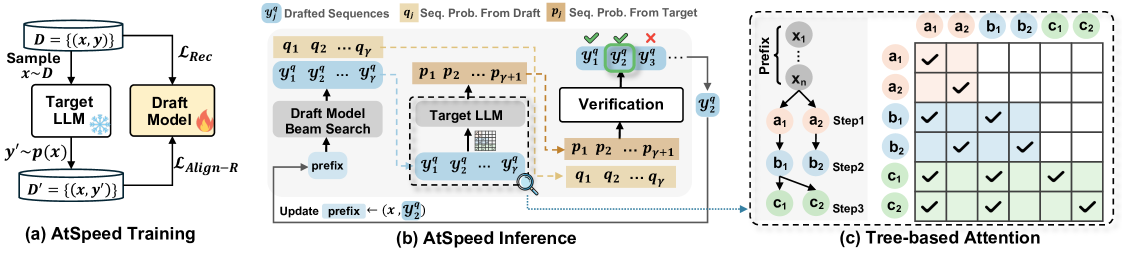
Overview of the AtSpeed framework, illustrating the drafting phase by a small model and the verification phase by the target LLM under N-to-K verification.
Evaluation Highlights
- Achieves ~2x speedup under strict Top-K verification on real-world datasets compared to standard decoding
- Up to 2.5x speedup using the proposed relaxed sampling verification strategy
- Maintains recommendation accuracy (Recall/NDCG) comparable to the target LLM while significantly reducing latency
Breakthrough Assessment
8/10
First paper to address Speculative Decoding specifically for beam search (N-to-K verification) in recommendation. The relaxed verification strategy is a practical and effective innovation for this specific constraint.