📝 Paper Summary
Tabular Data Synthesis
Recommender Systems
SampleLLM improves LLM-based tabular data synthesis for recommender systems by aligning the synthetic data distribution with the original data through chain-of-thought prompting and feature attribution-based importance sampling.
Core Problem
Existing tabular synthesis methods struggle with sparse recommendation data, and LLM-based approaches often produce data with inconsistent distributions and lack of diversity due to misalignment between the LLM's inherent knowledge and the target dataset.
Why it matters:
- Recommender systems suffer from data sparsity (cold start), severely limiting model performance.
- Traditional statistical/deep learning synthesis methods fail to capture semantic feature relationships essential for modern recommendation models.
- Directly prompting LLMs for data often results in biased distributions that degrade downstream model utility rather than enhancing it.
Concrete Example:
When using limited exemplars, a simplistic random selection for few-shot learning might overlook important regions of the original dataset (e.g., rare user-item interactions), leading to reduced output diversity and a mismatch in feature distributions as shown in the paper's motivational figure.
Key Novelty
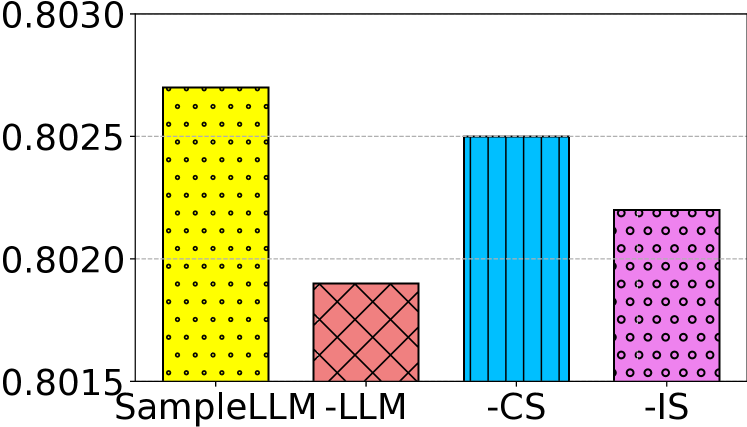
Two-stage Distribution Alignment Framework (SampleLLM)
- Stage 1: Uses Chain-of-Thought refined instructions and cluster-based exemplar sampling to generate diverse initial synthetic data that better captures semantic relationships.
- Stage 2: Applies a novel feature attribution-based importance sampling method to re-weight synthetic samples, ensuring their statistical distribution matches the original dataset's key feature interactions.
Architecture
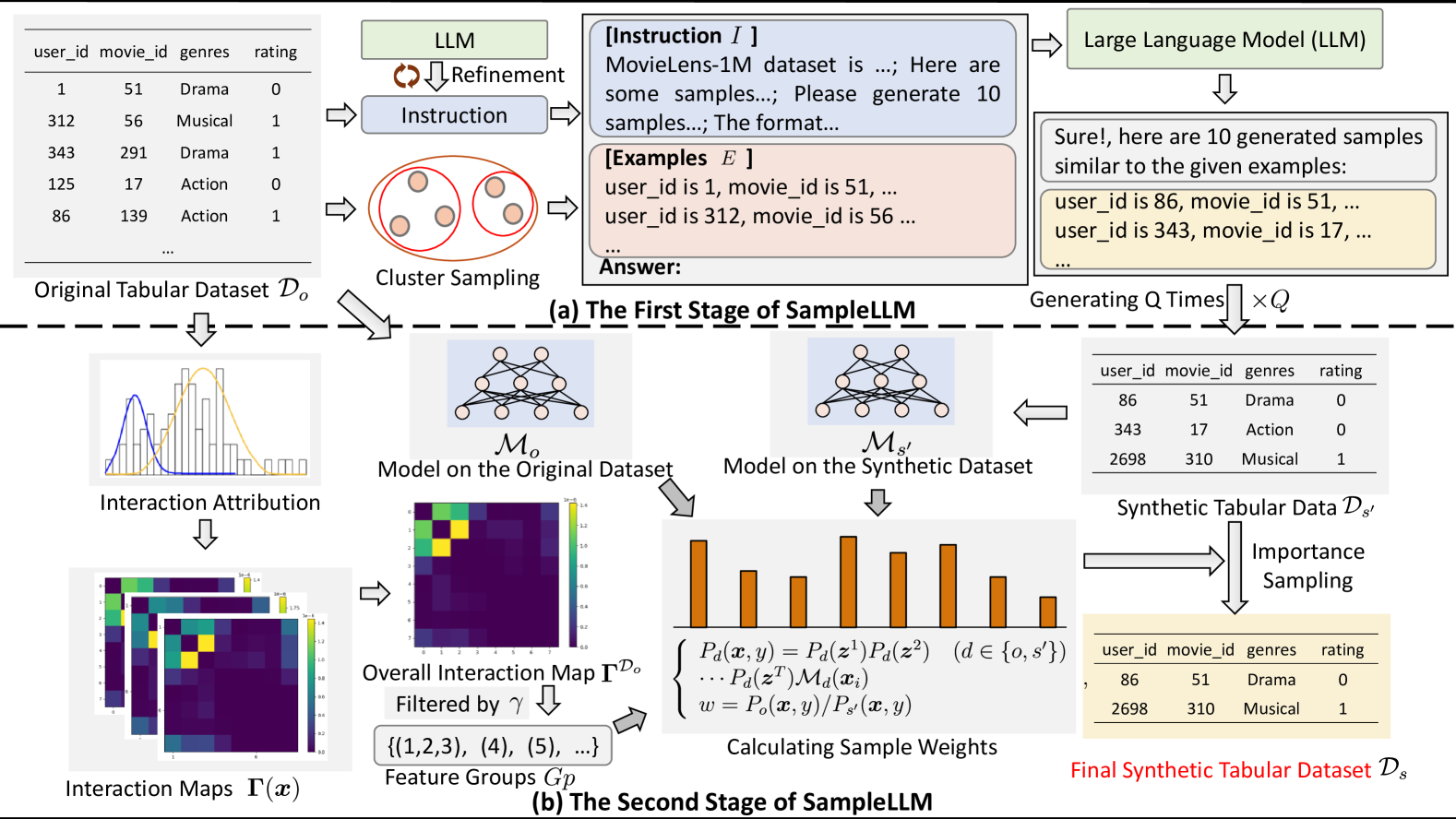
The two-stage framework of SampleLLM. Stage 1: LLM-based generation with refined instructions and cluster-sampled exemplars. Stage 2: Distribution alignment via feature attribution and importance sampling.
Evaluation Highlights
- Outperforms state-of-the-art baselines (including Tabula and GReaT) on 3 recommendation datasets and 2 general tabular datasets.
- Online deployment in a Huawei app scenario showed a +1.45% improvement in CTR (Click-Through Rate) and +1.18% in CVR (Conversion Rate).
- Achieves superior machine learning efficacy (MLE), meaning models trained on SampleLLM's synthetic data perform closer to models trained on real data compared to other synthesis methods.
Breakthrough Assessment
7/10
Significant practical contribution by addressing the specific distribution alignment issues of LLMs in tabular data. The two-stage approach is methodologically sound and validated in a real-world online setting.