📝 Paper Summary
Generative Recommendation
Reinforcement Learning with Verifiable Rewards (RLVR)
LLM-based Recommendation
ReRe adapts reinforcement learning to generative recommendation by using constrained beam search for efficient negative sampling and an explicit ranking reward to penalize hard negatives.
Core Problem
Existing generative recommenders rely on low-quality negative sampling (random or static) and implicit likelihood-based rewards, leading to weak supervision and poor discriminative ability.
Why it matters:
- Implicit rewards in methods like DPO are based on likelihood margins rather than true user preferences, making them prone to reward hacking where metrics improve but recommendation quality drops
- Standard RLVR (like GRPO) fails in recommendation because the constrained item space leads to duplicate samples (low efficiency) and sparse binary rewards (all negatives get zero reward)
Concrete Example:
In a standard RLVR setup for recommendation, a model might sample 16 items. If the target is 'Item A', and the model generates 'Item A' once and 'Item B' (an irrelevant item) 15 times, standard rule-based rewards assign 1 to 'Item A' and 0 to all 'Item B's. This treats all negatives equally, ignoring that some might be 'harder' (more plausible) negatives that require stronger penalties.
Key Novelty
Reinforced Preference Optimization for Recommendation (ReRe)
- Integrates constrained beam search into the RLVR sampling phase to efficiently generate diverse, valid, and hard negative items in a single pass, avoiding the redundancy of random sampling
- Augments binary rule-based rewards with a 'ranking reward' that penalizes generated negatives based on their probability rank, providing fine-grained supervision beyond simple correctness
Architecture
The ReRe framework pipeline contrasting standard generation with the ReRe training process.
Evaluation Highlights
- Achieves relative gains of 27.13% on Amazon Toys and 12.40% on Amazon Industrial datasets compared to traditional and LLM-based baselines
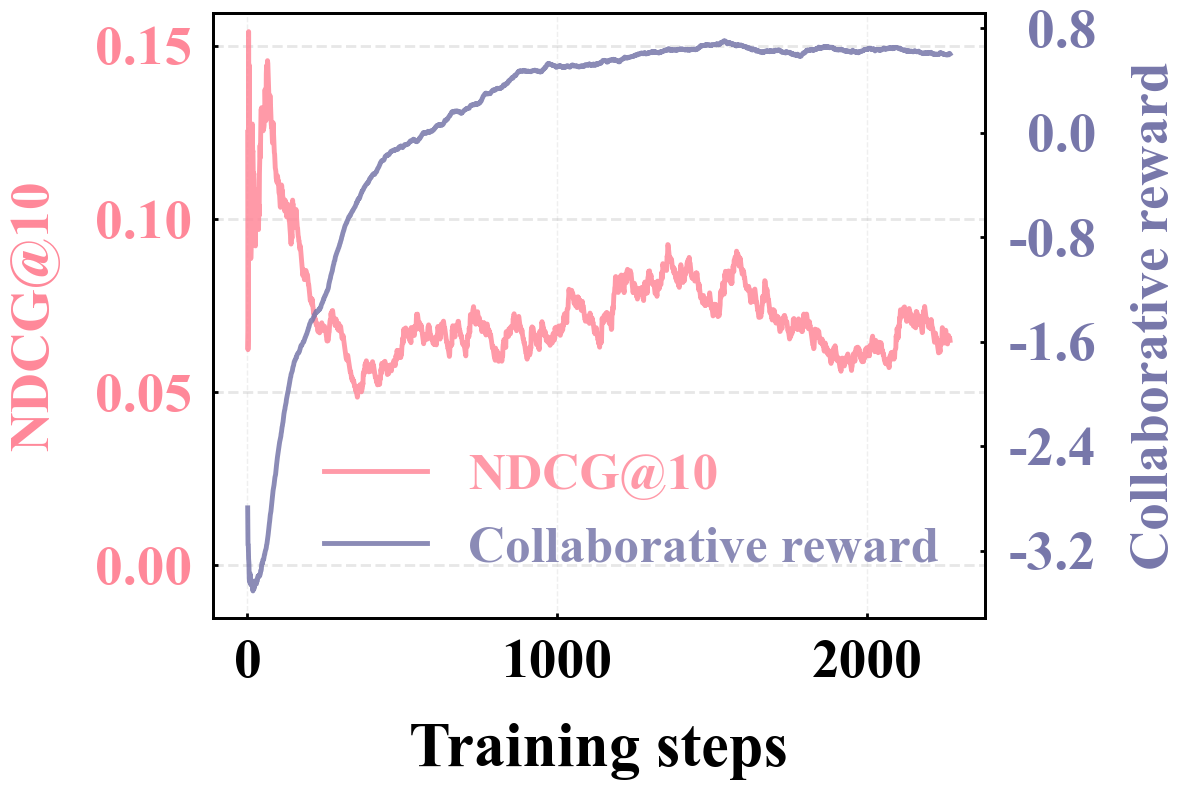
- Ranking reward formulation further improves NDCG@K by 3.95% on Amazon Toys compared to standard rule-based rewards, validating the benefit of fine-grained supervision
- Generalizes effectively across both base LLMs and SFT-initialized models, outperforming methods like D3 and S-DPO
Breakthrough Assessment
8/10
Successfully adapts RLVR (a hot topic in reasoning) to recommendation by addressing domain-specific challenges (constrained space, sparse rewards). Strong empirical gains and clear methodological motivation.