📝 Paper Summary
Multi-agent
Multi-turn w. user interactions
MACRS employs a team of LLM-based agents—three responders and one planner—to dynamically plan dialogue acts and reflect on user feedback for more effective conversational recommendation.
Core Problem
Single LLM-based Conversational Recommender Systems often struggle to control goal-directed dialogue flow (aimless chit-chat vs. recommendation) and fail to leverage user feedback to correct mistakes.
Why it matters:
- Existing attribute-based systems lack flexibility, while generation-based systems often lose focus on the recommendation goal
- Current LLM-only approaches fail to separate the distinct 'thinking' required for planning dialogue acts (asking vs. recommending) from generating the response content
- User feedback, which contains critical signals about why a recommendation failed, is typically ignored rather than used to update the system's strategy in real-time
Concrete Example:
When a user vaguely asks for 'classic films' and rejects a recommendation, a standard LLM might randomly guess another movie. MACRS's reflection module analyzes the rejection, updates the plan to 'ask' for clarification on the release era, and the planner agent selects the asking responder's output.
Key Novelty
Multi-Agent Act Planning & Feedback-Aware Reflection
- Decomposes the CRS task into specialized agents: 'Responder' agents generate candidate responses for different acts (ask, chat, recommend), while a 'Planner' agent reasons over history to select the best act
- Implements a 'Reflection' mechanism that analyzes user feedback to update user profiles (information-level) and generate strategic error summaries (strategy-level) when recommendations fail
Architecture
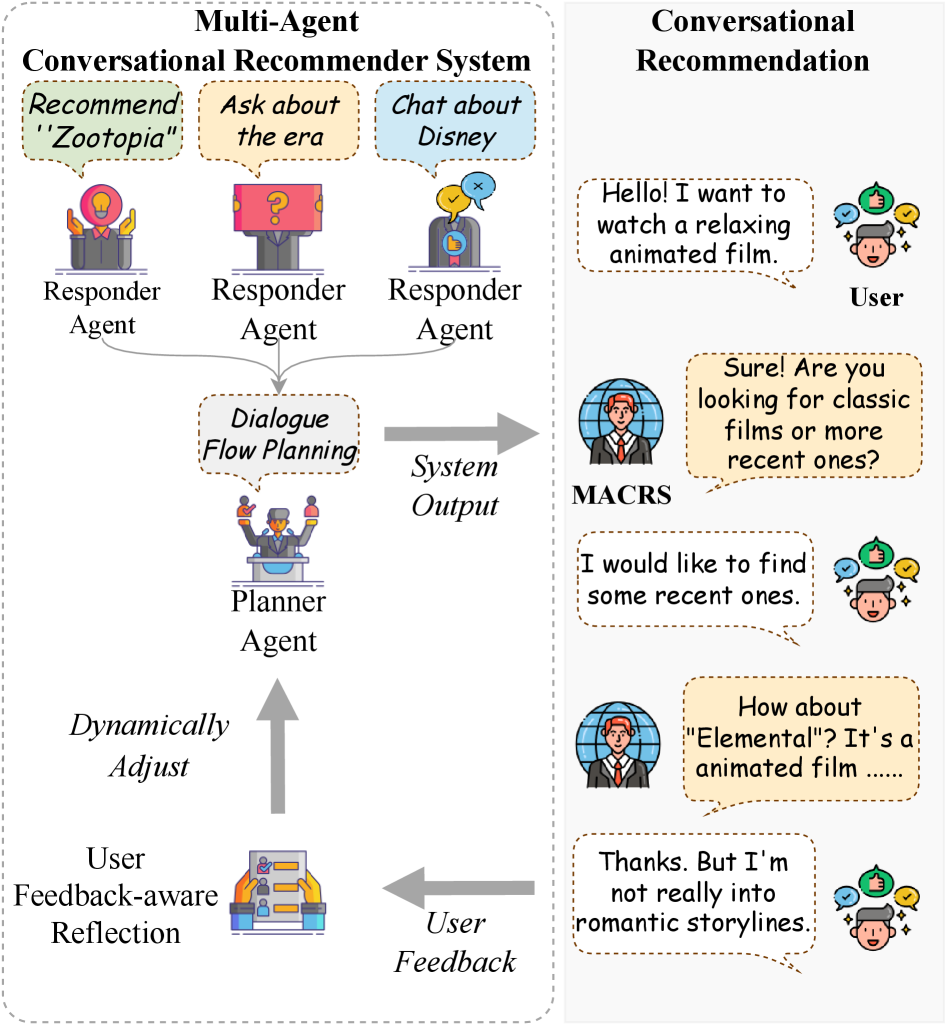
Overview of the MACRS framework showing the interaction between User, Reflection Mechanism, and Multi-Agent Act Planning.
Evaluation Highlights
- Outperforms state-of-the-art LLM-based CRS (ChatGPT, BARCOR) by notable margins on success rate (SR@1) and user preference collection efficiency
- Achieves higher Success Rate (SR@1) than the strongest baseline (BARCOR) on the ReDial dataset, demonstrating better recommendation accuracy
- Ablation studies confirm that removing the multi-agent planning or reflection modules significantly drops performance, validating the architectural design
Breakthrough Assessment
7/10
Strong conceptual advance in applying multi-agent patterns (planning + reflection) to CRS. Results are promising, though reliance on a user simulator for evaluation limits real-world validation.