📝 Paper Summary
Sequential Recommendation
LLM for Recommendation
Zero-shot Recommendation
STAR is a training-free recommendation framework that combines LLM-derived semantic embeddings with collaborative co-occurrence signals to retrieve items, followed by LLM-based pair-wise ranking for refinement.
Core Problem
Fine-tuning LLMs for recommendation is computationally expensive, while zero-shot LLM prompting performs poorly because it fails to capture the collaborative signals (user-item interaction patterns) essential for high-quality recommendations.
Why it matters:
- Current state-of-the-art methods rely on costly fine-tuning and significant engineering complexity
- Directly using LLMs (prompting) results in large quality drops due to the absence of collaborative knowledge (understanding what similar users liked)
- Existing hybrid approaches often still require training to align semantic and collaborative features
Concrete Example:
If a user buys a specific 'Lego set', a purely semantic LLM might suggest generic 'Plastic bricks' based on text similarity. However, collaborative data shows that users who bought that Lego set also bought a specific 'Display Case'. STAR captures this co-occurrence without training, whereas standard prompting misses it.
Key Novelty
Simple Training-free Approach for Recommendation (STAR)
- Explicitly incorporates collaborative knowledge into a training-free retrieval scorer by computing a normalized co-occurrence matrix of user interactions
- Combines this collaborative score with LLM-based semantic similarity, a temporal decay factor, and rating weights to rank candidate items without any gradient updates
- Utilizes a sliding-window pair-wise ranking strategy with an LLM to refine the order of retrieved items based on reasoning and popularity context
Architecture
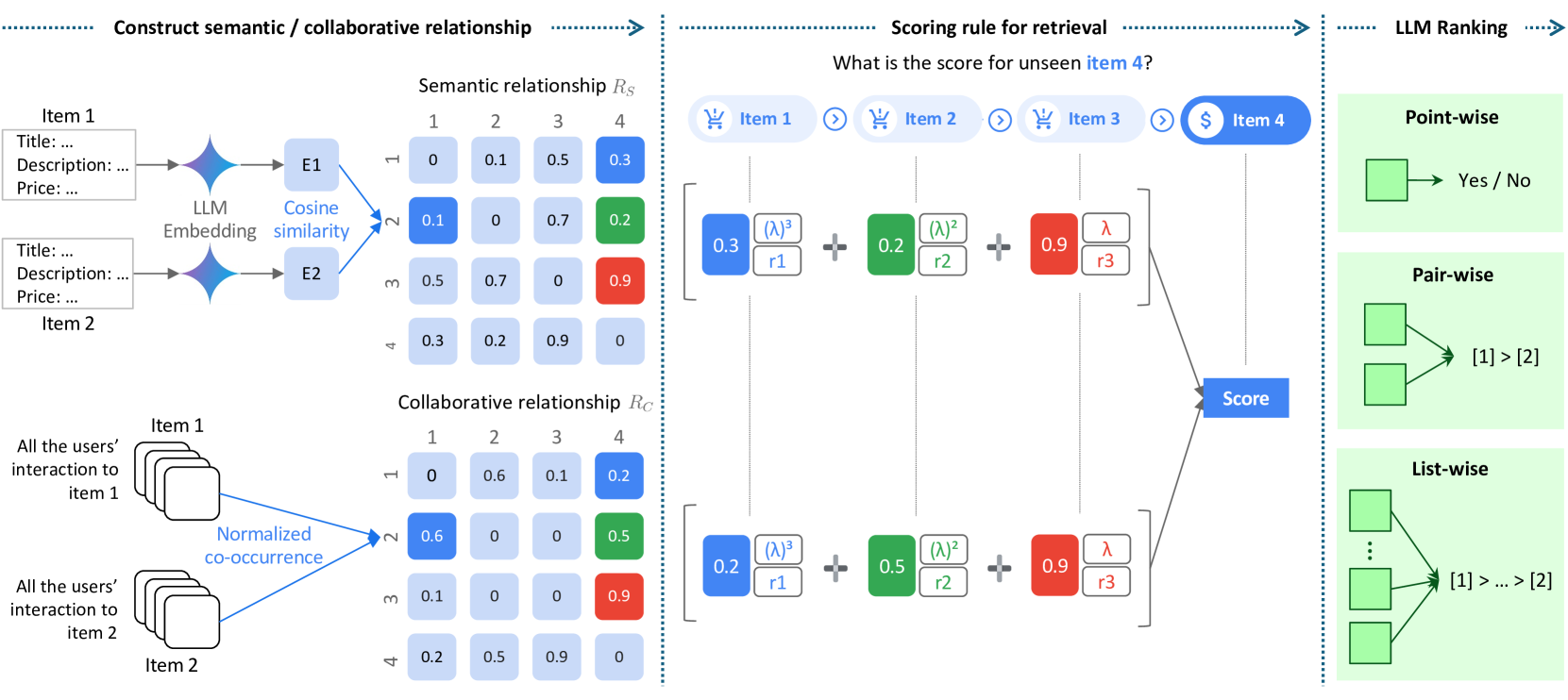
The STAR framework workflow, illustrating the calculation of scores for unseen items using item history.
Evaluation Highlights
- +37.5% improvement in Hits@10 on the Amazon Toys & Games dataset relative to the best supervised models (e.g., DuoRec, SASRec)
- +23.8% improvement in Hits@10 on the Amazon Beauty dataset relative to the best supervised models
- Retrieval stage alone (without LLM ranking) achieves +17.3% Hits@10 on Beauty compared to supervised baselines, proving the effectiveness of the hybrid scoring rule
Breakthrough Assessment
7/10
Significant because it demonstrates that training-free methods can outperform fully supervised baselines by effectively combining semantic and collaborative signals, challenging the assumption that fine-tuning is necessary for SOTA recommendation.