📝 Paper Summary
Data attribution
Fact checking
Interpretability
OLMoTrace is a real-time system that traces language model outputs back to verbatim matches in multi-trillion-token training corpora using a fast parallel suffix array search.
Core Problem
Tracing LM outputs to training data is critical for understanding behavior, but existing methods like influence functions are too computationally expensive to scale to multi-trillion-token corpora in real time.
Why it matters:
- Users need to understand why models generate specific responses, especially in high-stakes scenarios like fact-checking or detecting hallucination
- Current behavior tracing methods are too slow or resource-heavy for interactive use with modern massive datasets (trillions of tokens)
- Fully open models provide data access, but lack efficient tools to navigate that data verbatim at scale
Concrete Example:
If a model outputs 'The space needle was built for the 1962 World Fair', a user might want to know if this is a hallucination or a memorized fact. Without OLMoTrace, searching 3.2 billion documents for this exact string is infeasible; OLMoTrace finds the original web source instantly.
Key Novelty
Real-time Verbatim Training Data Tracing via Suffix Arrays
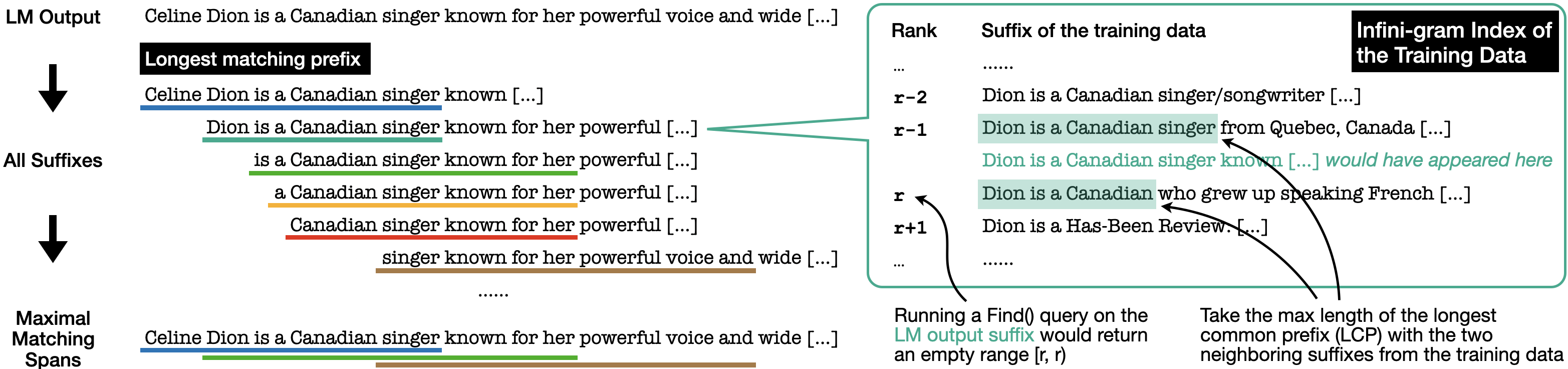
- Indexes the entire multi-trillion token training corpus using a suffix array (via infini-gram) to allow constant-time existence checks
- Uses a novel parallel algorithm to find all maximal matching spans in a generated response by checking the longest common prefix of suffixes in a single pass
- Filters matches by 'span unigram probability' rather than just length to identify unique, statistically significant phrases
Architecture
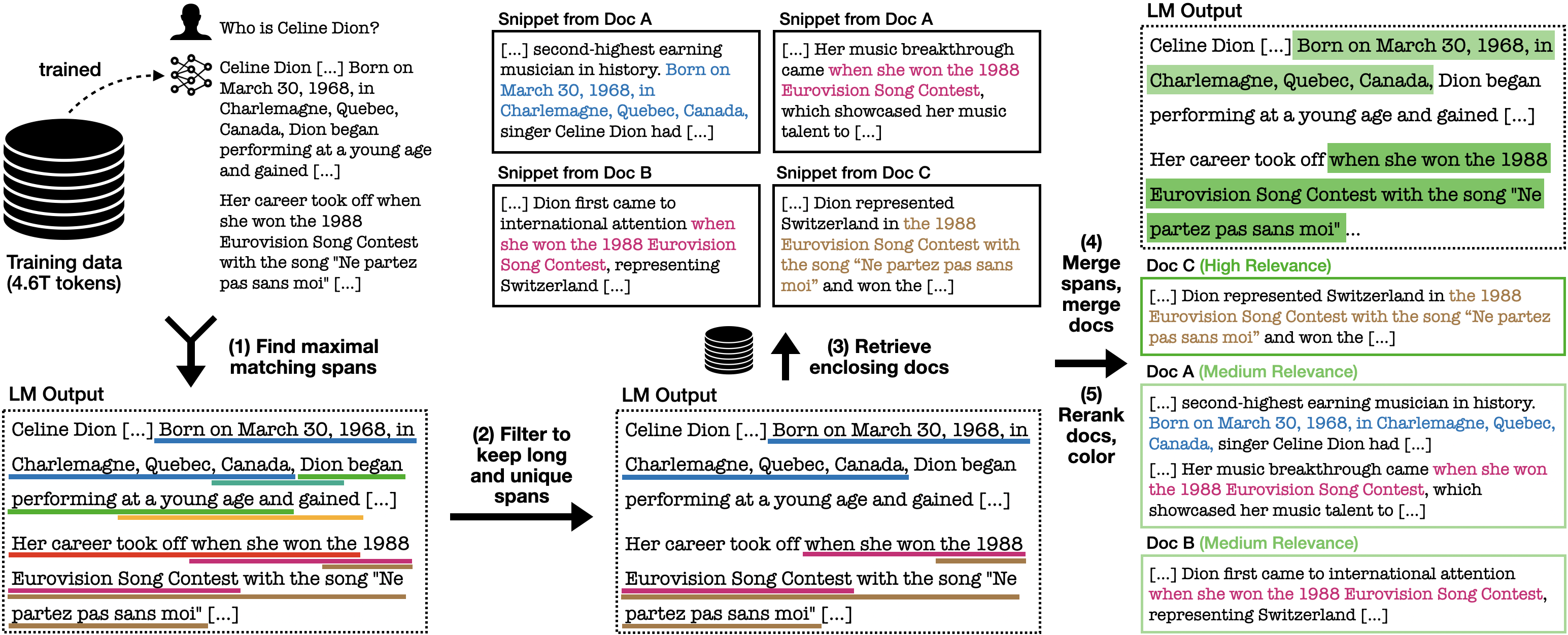
The five-step inference pipeline of OLMoTrace
Evaluation Highlights
- Achieves average inference latency of 4.46 seconds per query on OLMo-2-32B-Instruct responses (~450 tokens), enabling real-time user interaction
- Retrieves documents with high relevance to the generation: 14% of retrieved documents are classified as 'high relevance' (BM25 score ≥ 0.7)
- Strong alignment between retrieved documents and human relevance judgments (Spearman correlation of 0.73 with GPT-4o-based judging)
Breakthrough Assessment
8/10
First system to demonstrate real-time verbatim tracing against multi-trillion-token corpora. While limited to verbatim matches (not semantic influence), the engineering scale and speed enable a new class of interactive analysis tools.