📝 Paper Summary
Sequential Recommendation
LLM for Recommendation
HLLM decouples recommendation into an Item LLM that compresses text into embeddings and a User LLM that models interests over these embeddings, achieving scalability and efficiency.
Core Problem
Directly inputting user history text into LLMs creates excessively long sequences, causing quadratic complexity growth and inefficiency, while traditional ID-based models struggle with cold starts and shallow modeling capabilities.
Why it matters:
- LLMs' self-attention complexity scales quadratically with sequence length, making long user history text input computationally prohibitive
- Existing LLM-based recommenders often fail to significantly outperform traditional methods, questioning the value of pre-trained weights
- Scalability of billion-parameter models in recommendation remains under-explored compared to other domains
Concrete Example:
Recommending a single item using a standard text-in/text-out LLM requires generating multiple tokens and multiple forward passes, which is slow. Additionally, representing a long history of user behaviors as raw text results in a context length far exceeding that of ID-based sequences, slowing down training and inference.
Key Novelty
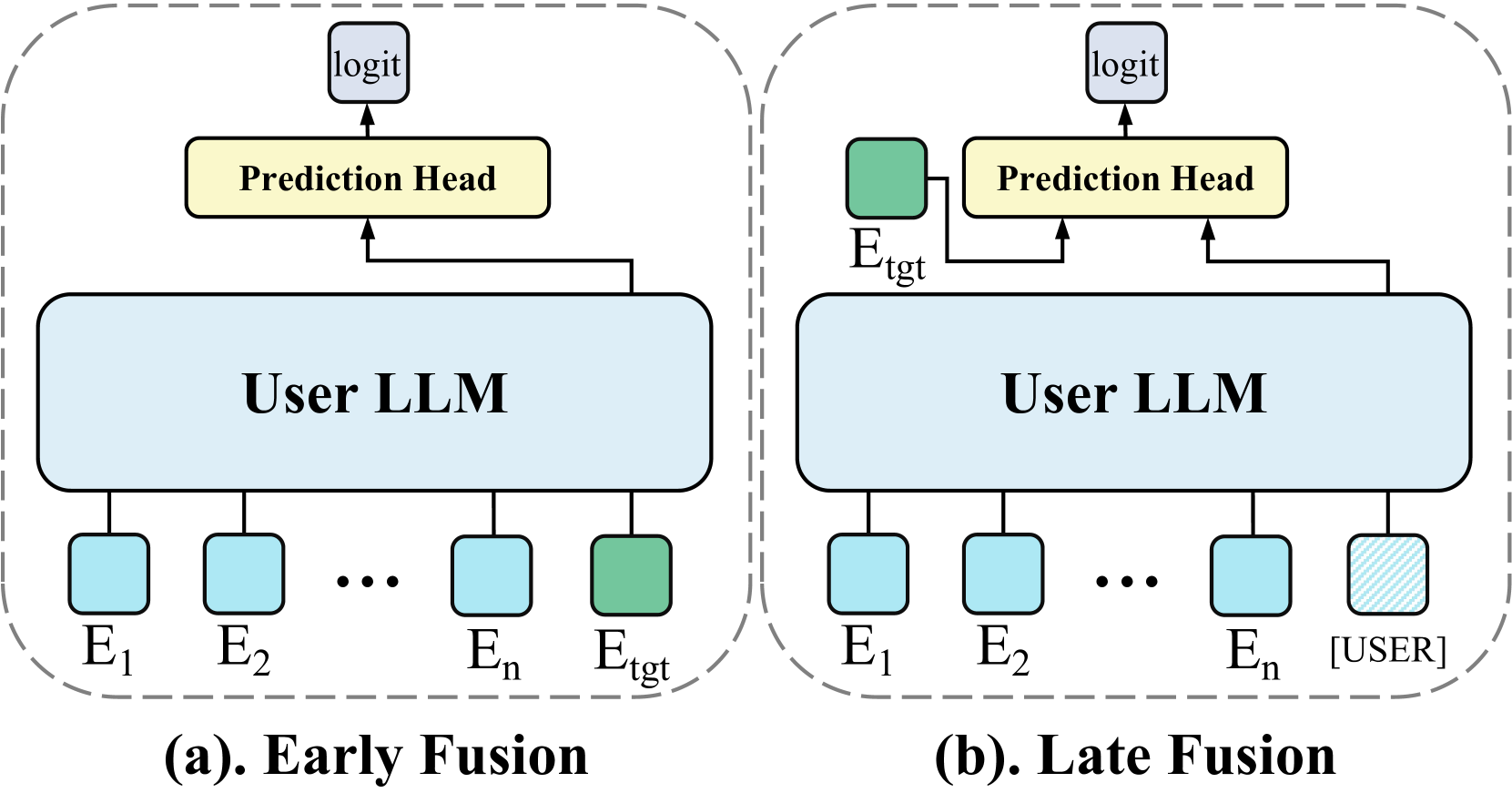
Hierarchical Large Language Model (HLLM)
- Decouples the task into two tiers: an Item LLM that acts as a feature extractor converting item text to embeddings, and a User LLM that processes these embeddings to predict user interests.
- Uses a special token [ITEM] to compress detailed item descriptions into concise vectors, reducing the user sequence length to match efficient ID-based models while retaining semantic richness.
Architecture
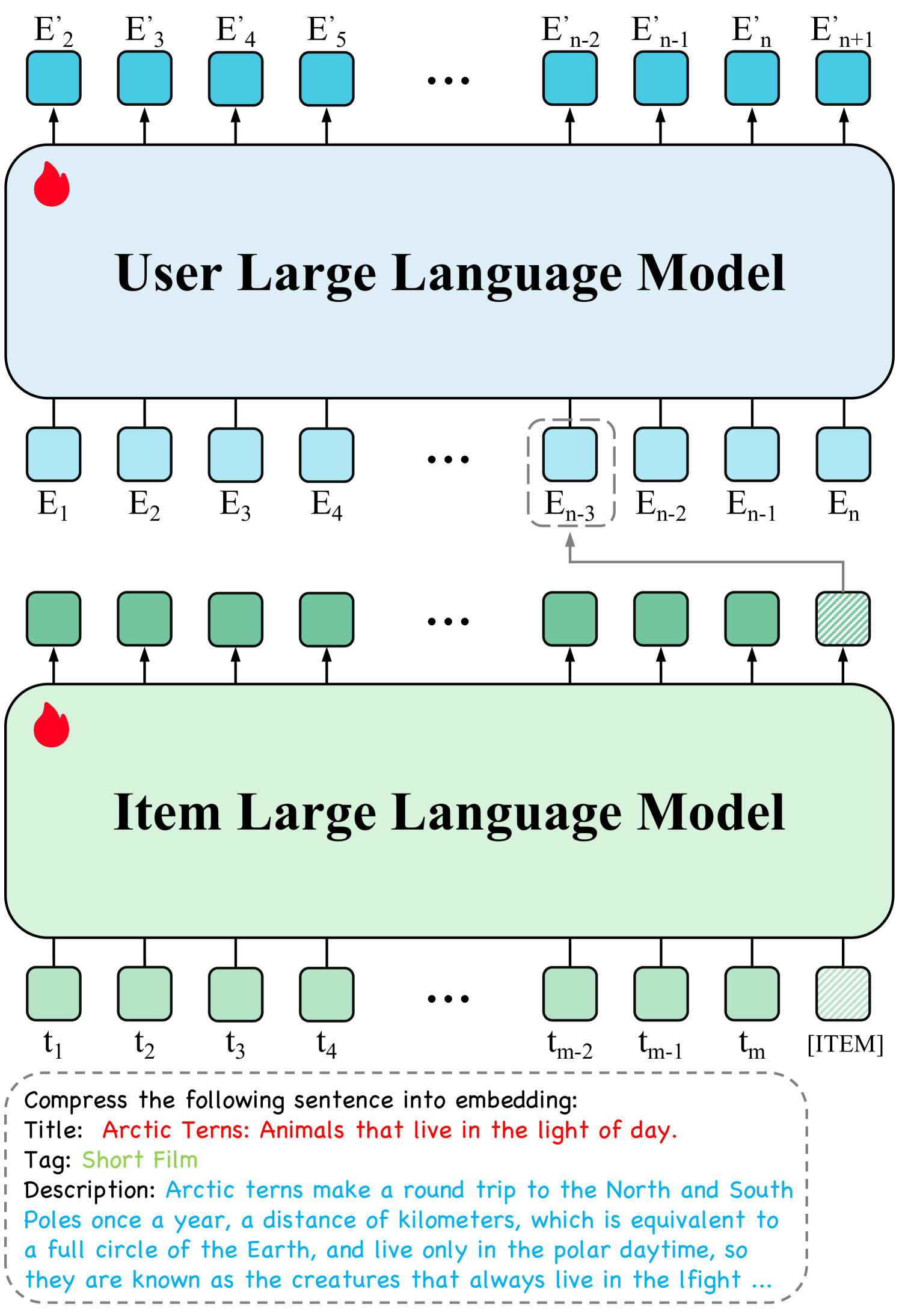
The hierarchical architecture of HLLM. It shows the Item LLM processing item text to generate an embedding (via [ITEM] token) and the User LLM processing a sequence of these item embeddings to predict the next item embedding.
Evaluation Highlights
- Significantly outperforms traditional ID-based models (SASRec) and LLM-based baselines on PixelRec and Amazon Reviews datasets.
- Scaling the User LLM from 1B to 7B parameters yields consistent performance gains, validating scaling laws in recommendation.
- Achieves state-of-the-art results with high training efficiency, surpassing ID-based models with only a small fraction of training data.
Breakthrough Assessment
8/10
Successfully validates the scaling law for billion-parameter models in recommendation and offers a practical, efficient architecture that bridges the gap between ID-based efficiency and LLM semantic capabilities.