📝 Paper Summary
Conversational Recommender Systems (CRS)
Large Language Models (LLMs) for Recommendation
Reindex-Then-Adapt converts multi-token item titles in LLMs into single-token representations to enable efficient adjustment of recommendation probabilities toward target platform distributions.
Core Problem
LLMs recommend items by autoregressively generating multi-token titles, making it computationally expensive to calculate or adjust the full probability distribution over all items to match target platform popularity.
Why it matters:
- LLMs trained on general corpora often recommend items (e.g., 'Black Panther') that do not match the popularity distribution of specific target platforms (e.g., ReDIAL dataset)
- Target data distributions evolve rapidly (e.g., monthly popularity shifts), requiring efficient adaptation without full retraining
- Current generative retrieval methods prevent easy access to full-item logits needed for standard RecSys control techniques
Concrete Example:
In the ReDIAL dataset, 'The Dark Knight' is very popular, but a standard Llama-7b model rarely recommends it. Conversely, 'Black Panther' is over-recommended by the LLM compared to its actual popularity on the platform. The multi-token generation of 'The Dark Knight' makes it hard to simply boost its probability score globally.
Key Novelty
Reindex-Then-Adapt (RTA) Framework
- Reindex Step: Squeezes multi-token item titles (e.g., 'Edge', 'of', 'Tomorrow') into a single token embedding using a contrastive aggregator, allowing the LLM to represent items as atomic units.
- Adapt Step: Once items are single tokens, the model can efficiently compute logits for all items and apply affine transformations (bias adjustments) or mix with traditional RecSys scores to match target distributions.
Architecture
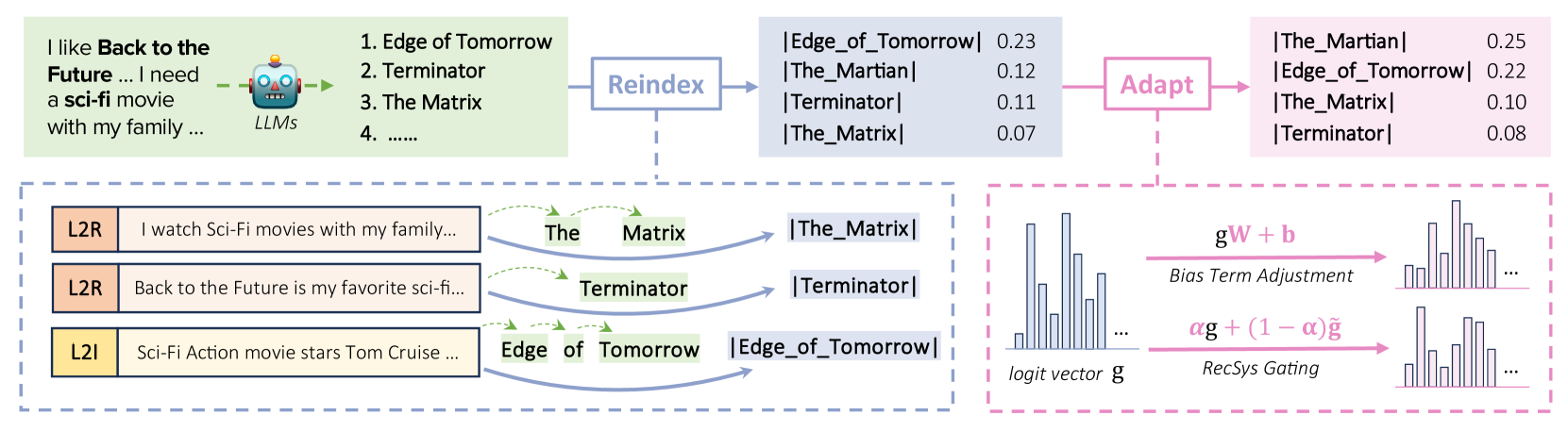
The Reindex-Then-Adapt (RTA) framework pipeline. It shows the transition from original LLM multi-token indexing to reindexed single-token embeddings, followed by the adaptation phase.
Evaluation Highlights
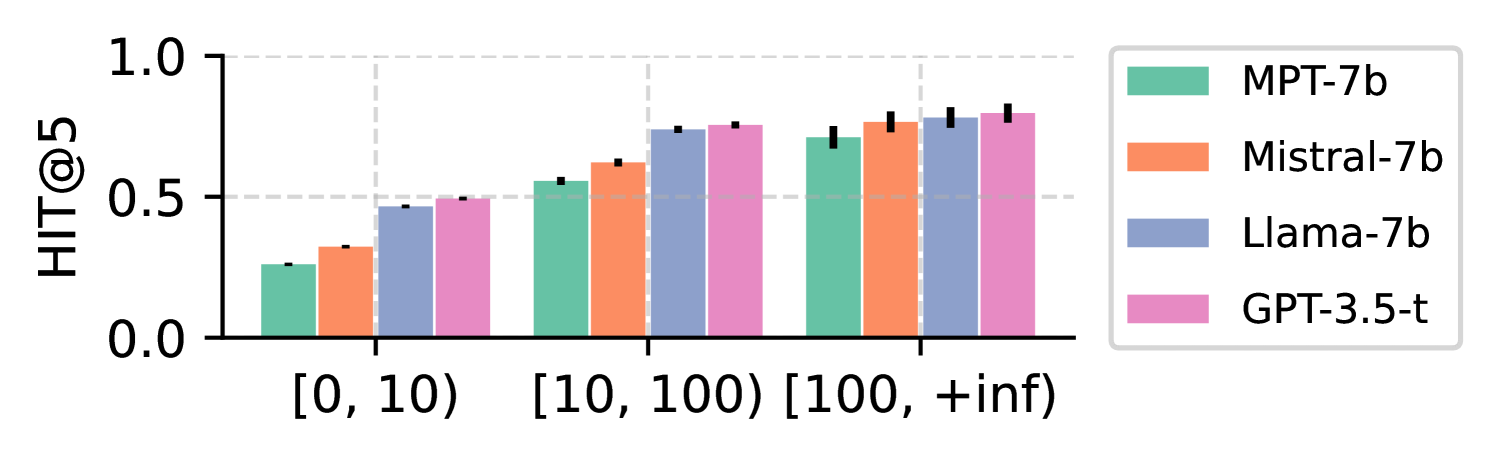
- +59.37% Top-10 Hit Rate improvement for Llama2-7b on the ReDIAL dataset using the RTA framework
- Surpasses all open-source baselines on ReDIAL, Reddit-Movie, and GoRecDial datasets
- Achieves better alignment with target item popularity distributions compared to vanilla LLMs
Breakthrough Assessment
8/10
Significantly addresses the 'generative vs. discriminative' gap in LLM recommendation by making generative logits accessible for control, showing massive empirical gains.