📊 Experiments & Results
Evaluation Setup
Sequential recommendation on MovieLens1M and Steam datasets
Benchmarks:
- MovieLens1M (Movie Recommendation)
- Steam (Game Recommendation)
Metrics:
- GP (Group Proportion)
- GU (Group Unfairness)
- MGU (Mean Group Unfairness)
- DGU (Disparity Group Unfairness)
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
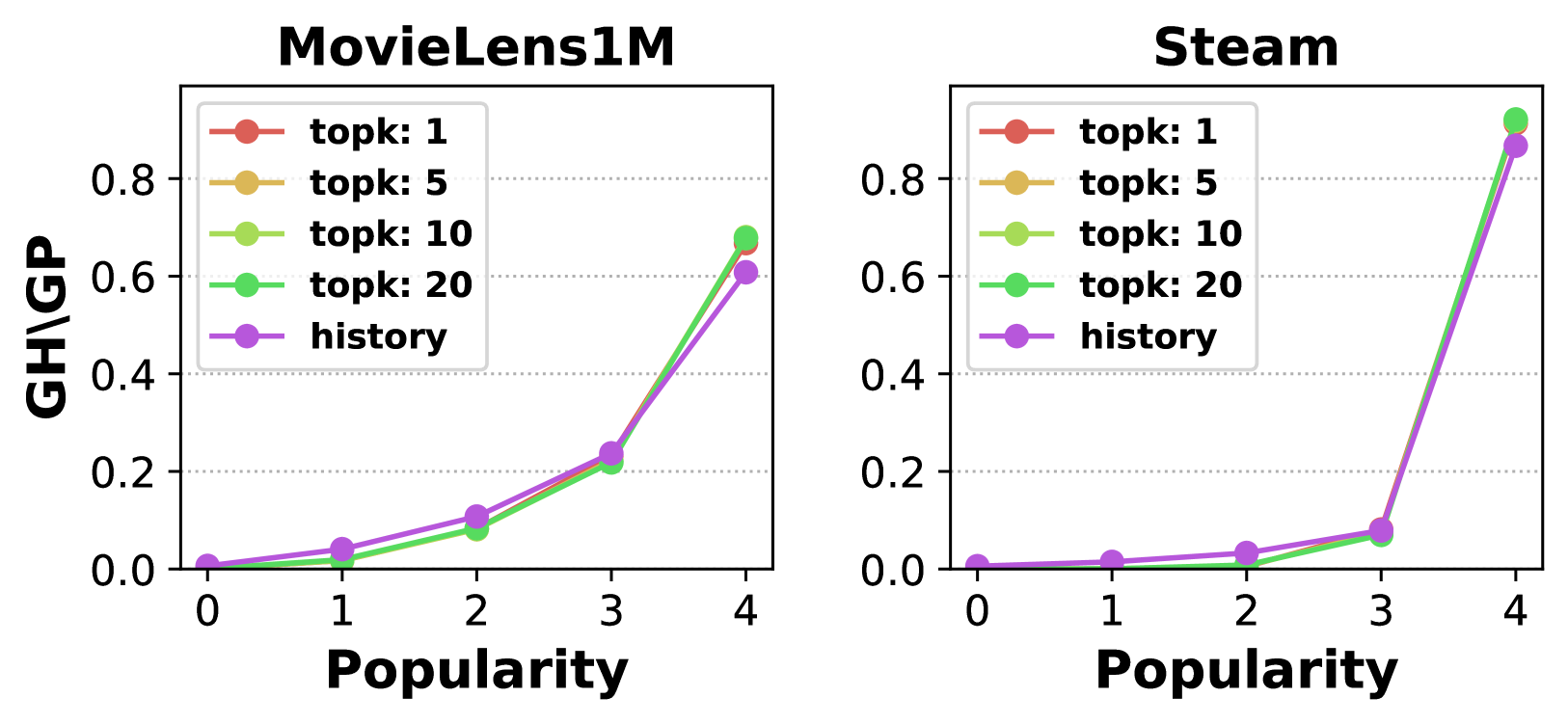
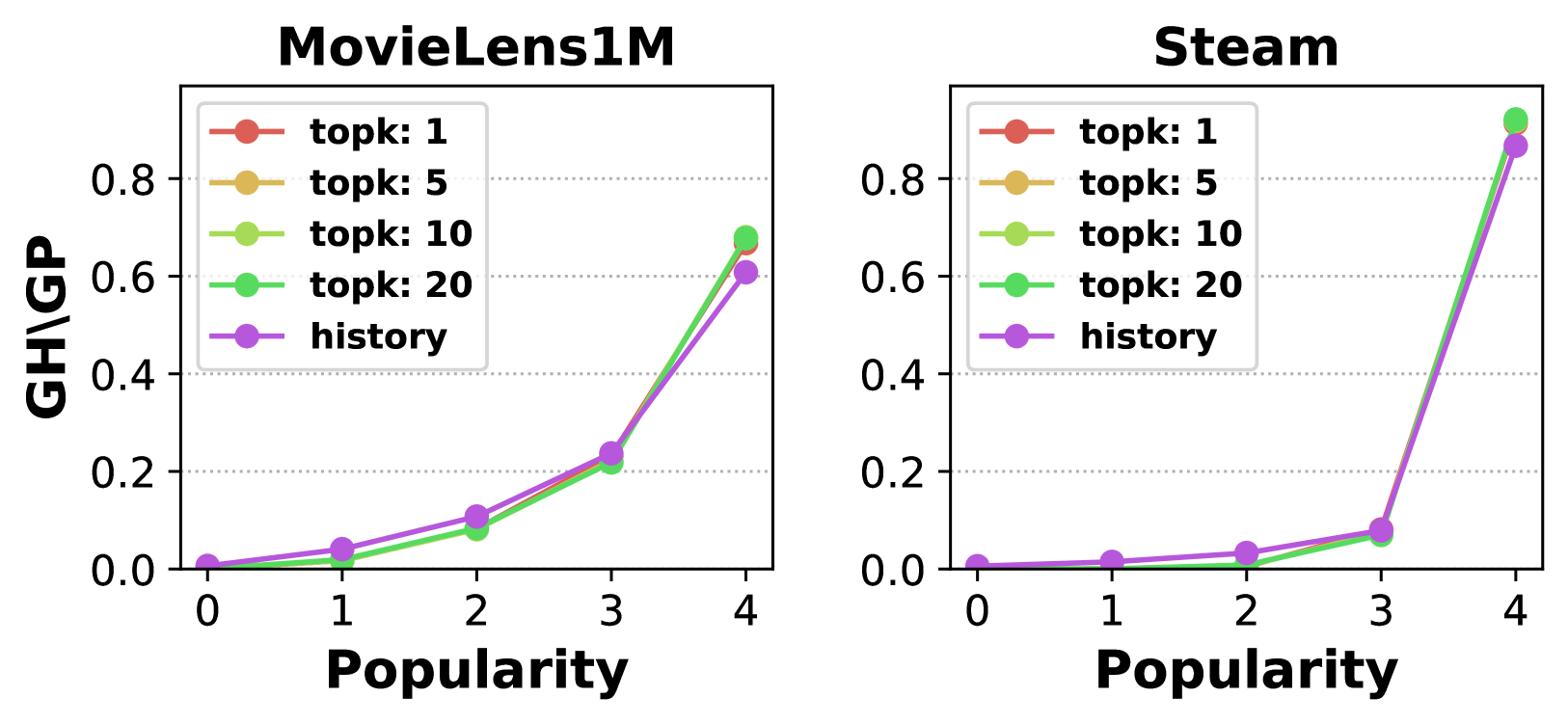
Comparison of item popularity distribution in recommendations vs. history for MovieLens1M and Steam
Impact of removing specific genres from training data on recommendation probability
Main Takeaways
- LRS (BIGRec) is significantly more unfair than traditional models (SASRec) regarding popularity, consistently over-recommending popular items.
- LRS exhibits semantic bias: it recommends items from genres (e.g., Comedy) even if those genres were removed from the fine-tuning data, indicating reliance on pre-trained knowledge.
- The 'Grounding' phase (mapping text to items) helps mitigate some unfairness for unpopular items but can inadvertently boost high-popularity groups.
- Increasing K (in Top-K) alleviates popularity unfairness in LRS as the grounding retrieves a wider range of items.