📝 Paper Summary
Dataset Condensation / Distillation
Content-based Recommendation (CBR)
LLM-based Data Synthesis
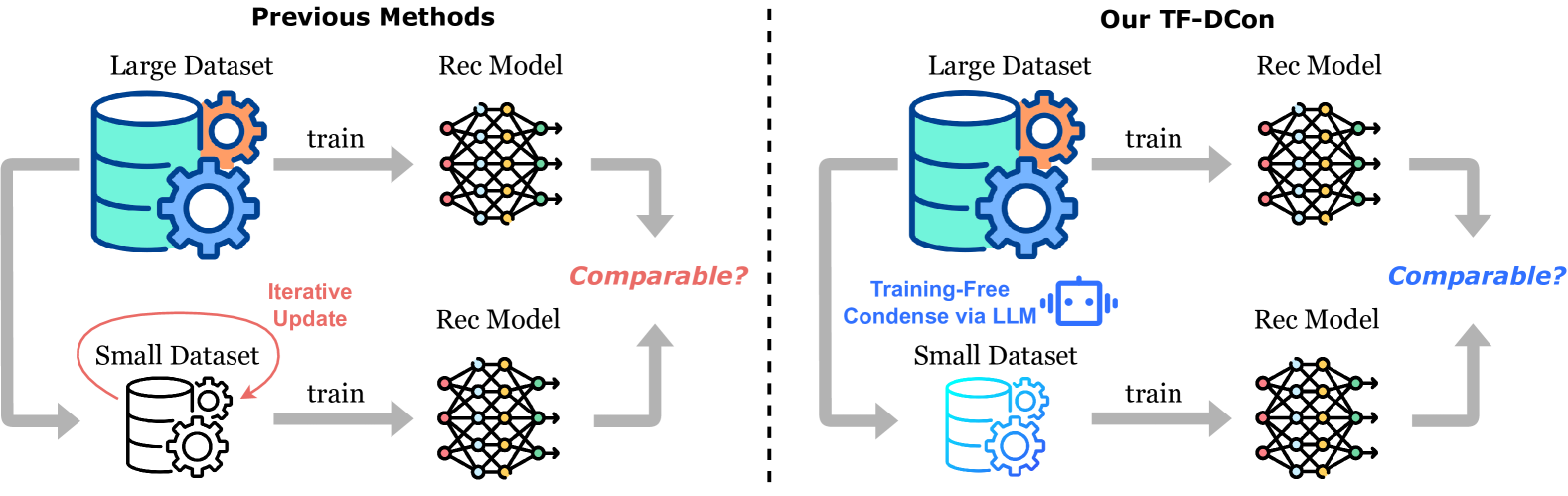
TF-DCon uses ChatGPT to synthesize a compact recommendation dataset by condensing item text and generating synthetic users via clustering, eliminating expensive bi-level optimization.
Core Problem
Existing dataset condensation methods rely on bi-level optimization that cannot handle discrete text generation and fail to preserve complex user-item preference information.
Why it matters:
- Training recommender models on large-scale datasets is resource-intensive and expensive, especially for frequent periodic updates.
- Current condensation techniques are designed for continuous data (images, embeddings) and cannot directly synthesize high-quality discrete textual content.
- Naive condensation often loses the essential collaborative signals (user-item interactions) required for accurate personalization.
Concrete Example:
Traditional methods like gradient matching can synthesize continuous embeddings but cannot generate a readable news title. A standard method might reduce a dataset but lose the link that 'User A likes Sci-Fi', whereas TF-DCon uses ChatGPT to extract 'Sci-Fi' interest and synthesize a user who clicks on Sci-Fi items.
Key Novelty
Training-Free Dataset Condensation (TF-DCon)
- Replaces iterative bi-level optimization with a one-pass forward synthesis pipeline, significantly reducing computational cost.
- Uses a prompt-evolution mechanism to guide ChatGPT in compressing verbose item descriptions into concise, informative titles.
- Synthesizes fake users and interactions by clustering real user embeddings and mapping them to items based on semantic interest matching.
Architecture
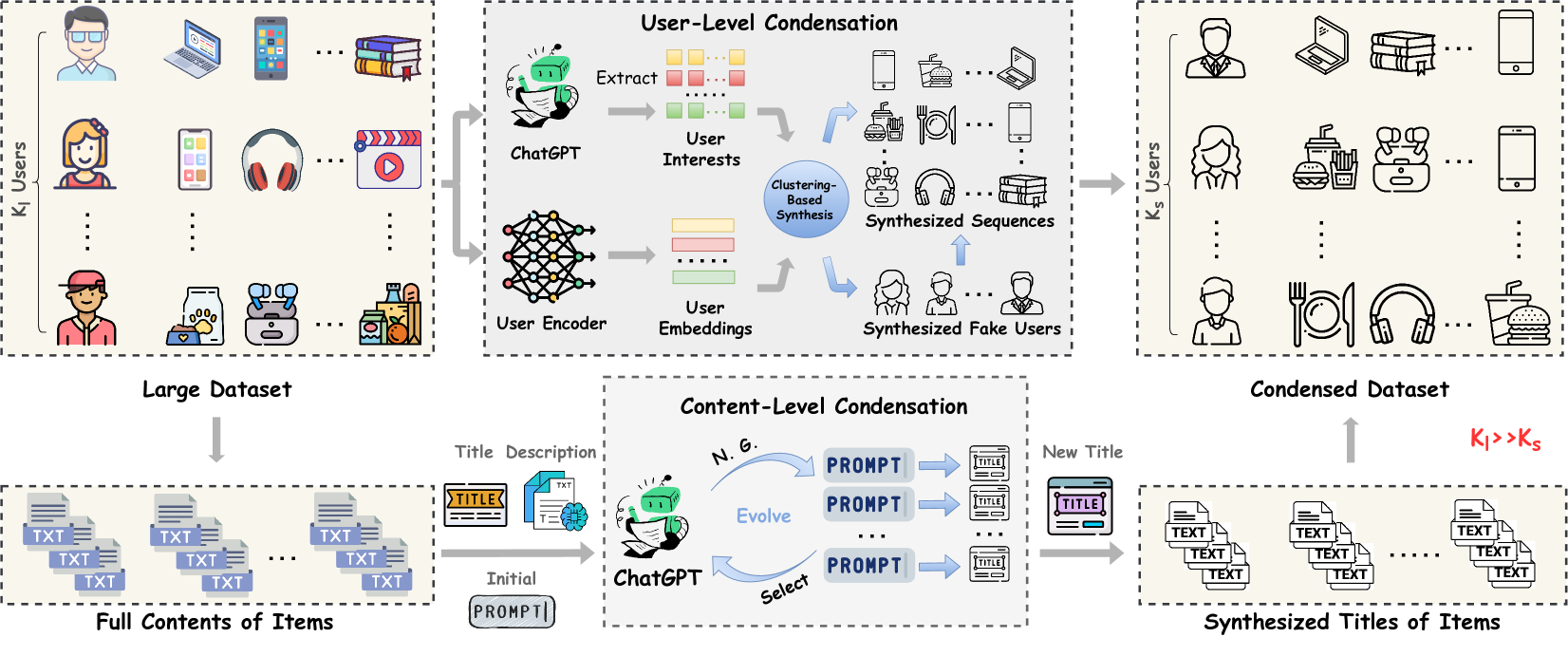
Overview of the TF-DCon framework, illustrating the two-level condensation process: Content-level (Item side) and User-level (User side).
Evaluation Highlights
- Approximates up to 97% of original model performance on the MIND dataset while reducing dataset size by 95% (20x compression).
- Achieves 5x speedup in model training time when using the condensed dataset compared to the full dataset.
- Outperforms state-of-the-art condensation baselines (e.g., random selection, K-center) on three real-world datasets (MIND, HM, GBR).
Breakthrough Assessment
7/10
First exploration of dataset condensation specifically for textual Content-Based Recommendation. The training-free, LLM-driven approach is a significant departure from standard gradient-matching paradigms.