📝 Paper Summary
Session-Based Recommendation (SBR)
Graph Neural Networks (GNN) in Recommendation
Large Language Models (LLM) for Recommendation
LLMGR bridges the gap between graph-based session recommendation and LLMs by using hybrid encoding and multi-task instruction tuning to help LLMs understand graph structures and item transition patterns.
Core Problem
Traditional SBR methods (like GNNs) capture structural item transitions but miss rich textual context, while LLMs understand text but struggle to process the specific graph structures inherent to session data.
Why it matters:
- SBR relies on limited interaction data, making it hard to infer intent without leveraging textual content (titles, descriptions)
- Existing LLM recommenders treat tasks as pure text generation, failing to utilize the collaborative signals and complex transition patterns captured by session graphs
- Bridging this gap allows systems to use both explicit structural patterns (from GNNs) and semantic knowledge (from LLMs) for better accuracy
Concrete Example:
In a user session [Item A -> Item B -> Item A -> Item C], a GNN easily captures the loop and transition structure but doesn't know Item C is 'organic milk'. An LLM knows 'organic milk' is healthy but sees the session as a flat text string, missing the cyclic graph structure that indicates strong re-purchase intent.
Key Novelty
LLMGR (Large Language Models with Graphical Session-Based Recommendation)
- Proposes a hybrid encoding layer that projects pre-trained graph node embeddings (IDs) into the LLM's token embedding space, allowing the LLM to 'see' both text and graph nodes
- Introduces a two-stage instruction tuning strategy: first aligning text with graph nodes (auxiliary task), then tuning on the main recommendation task using structure-aware prompts
Architecture
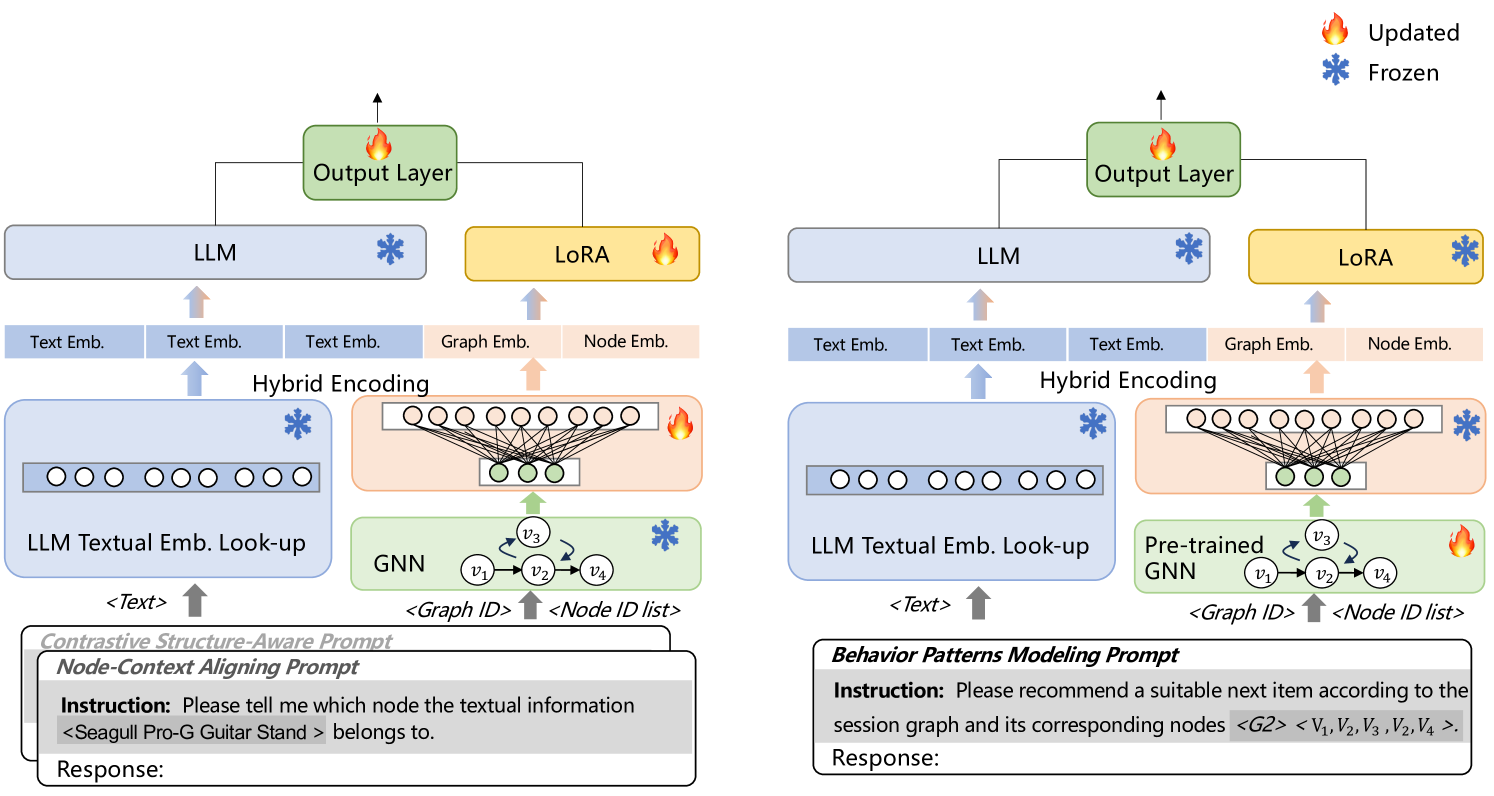
The overall architecture of LLMGR, illustrating the flow from session graph construction to LLM processing.
Evaluation Highlights
- Outperforms state-of-the-art GNN baselines (like HCGR) and LLM baselines on three real-world datasets
- Achieves best performance compared to competitive baselines (specific numeric margins not explicitly summarized in text, but claimed as 'significantly outperforms')
- Demonstrates portability by utilizing pre-trained embeddings from various conventional SBR methods (SR-GNN, GC-SAN, HCGR)
Breakthrough Assessment
7/10
Novel approach to the specific problem of feeding graph structures into LLMs via embedding projection. While it addresses a clear gap, it relies on pre-trained GNNs rather than fully end-to-end graph-LLM joint training.