📝 Paper Summary
Recommendation Re-ranking
LLM for Recommender Systems
LLMs can effectively re-rank candidate recommendations to improve diversity by following zero-shot prompts, though they currently trade off more relevance and incur higher costs than traditional greedy algorithms.
Core Problem
Recommender systems often produce relevant but homogeneous lists of items, failing to offer meaningful choice or handle uncertainty.
Why it matters:
- Pure relevance maximization ignores critical user satisfaction factors like novelty, serendipity, and fairness
- Traditional diversity methods (greedy re-ranking) require explicit feature engineering and hyperparameter tuning
- Existing LLM-based recommendation research focuses almost exclusively on relevance, neglecting beyond-accuracy objectives like diversity
Concrete Example:
A relevance-optimized recommender might suggest 10 very similar 'Action' anime movies to a user. Traditional methods re-rank this list using mathematical formulas to mix genres. This paper tests if an LLM can simply be told 'produce a diverse ranking' and achieve a similar result without explicit feature engineering.
Key Novelty
Zero-Shot LLM-based Diversity Re-ranking
- Frames the diversification problem as a text generation task where an LLM re-orders a candidate list based on natural language instructions
- Designs specific prompts that guide the LLM to balance relevance and diversity without needing training data or explicit distance metrics
- Introduces a methodology to handle LLM hallucinations (invalid items) in recommendation lists during evaluation
Architecture
The workflow of the proposed LLM-based diversity re-ranking approach.
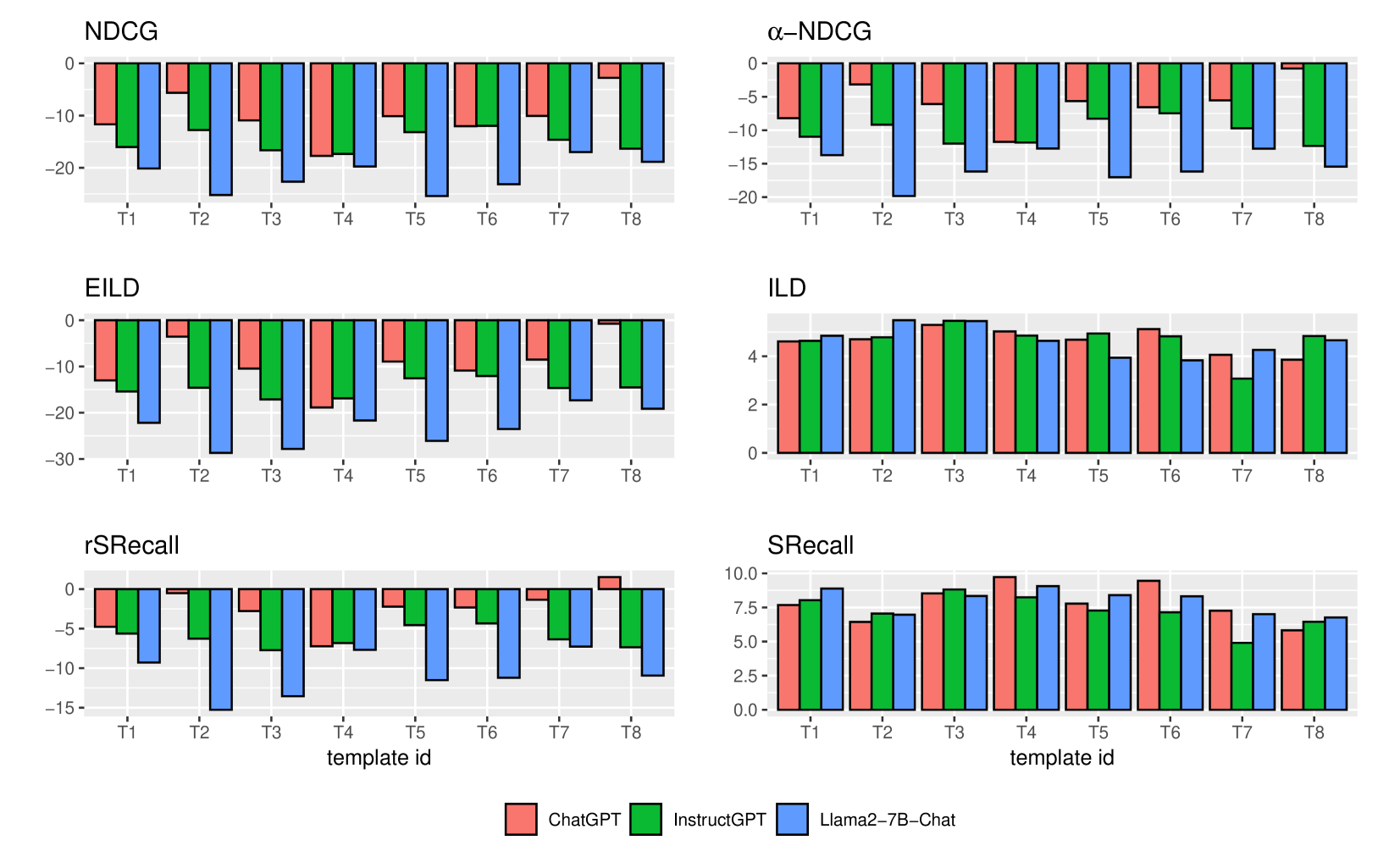
Evaluation Highlights
- ChatGPT enhances diversity metrics (e.g., +0.06 EILD) compared to the initial relevance-based ranking, though with a drop in relevance (-0.03 nDCG)
- OpenAI models (ChatGPT, InstructGPT) consistently outperform Llama2 models in following re-ranking instructions and minimizing hallucinations
- Feature-aware prompts (providing item genres) yield better trade-offs than simple high-level instructions
Breakthrough Assessment
4/10
First exploration of LLMs for diversity re-ranking. While promising, it does not yet beat traditional, faster greedy baselines, serving more as a feasibility study than a new SOTA.