📝 Paper Summary
Cold-start Recommendation
Data Augmentation
The paper utilizes Large Language Models to generate synthetic pairwise preferences for cold-start items based on user history, enabling standard ID-based recommenders to learn effective embeddings without real interactions.
Core Problem
Standard recommender systems rely on ID-based embeddings that require abundant historical interactions, causing them to fail on 'cold-start' items (newly uploaded content) where no such data exists.
Why it matters:
- Cold-start items (fresh content) are crucial for platform freshness but receive poor exposure in ID-based systems
- Content-based methods often fail to capture collaborative signals effectively
- Directly serving LLMs for recommendation is prohibitively expensive and slow for industrial scale
Concrete Example:
A user who bought 'Moroccan Argan Oil Conditioner' has no history with a newly uploaded 'Clump Crusher Mascara'. A standard ID-based model sees the new mascara as a random ID with no embedding, failing to predict the user's potential interest.
Key Novelty
LLM-based Offline Pairwise Data Augmentation
- Treats the LLM as a synthetic data generator rather than a recommender, using it to infer user preferences between pairs of cold-start items based on textual purchase history
- Augments the training of standard efficient models (like NeuMF) with these synthetic signals via an auxiliary loss, bypassing the need to run the LLM during serving
Architecture

The pairwise comparison prompt template used to generate synthetic training data
Evaluation Highlights
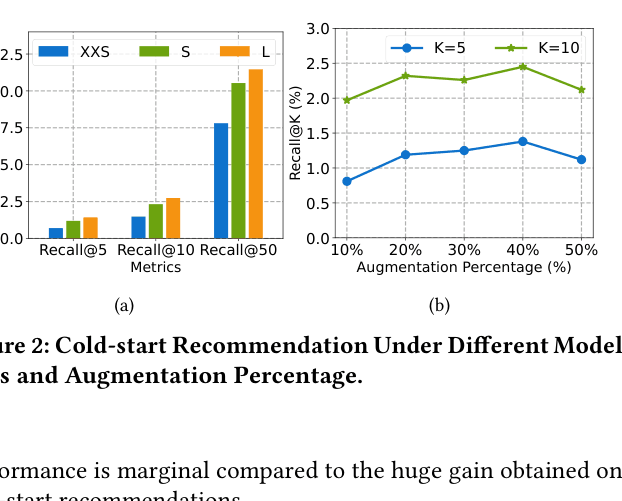
- Improves Recall@5 for cold-start items on the Amazon Beauty dataset from 0.14% (NeuMF baseline) to 1.19% (with augmentation), a nearly 8x improvement
- Boosts SASRec performance on Amazon Sports cold-start items from 0.10% to 0.37% Recall@5, significantly outperforming content-based baselines
- Maintaining performance on warm-start items (e.g., 3.35% vs 3.44% Recall@5 on Beauty) while drastically improving cold-start coverage
Breakthrough Assessment
7/10
Simple but highly effective strategy to bridge the gap between powerful LLMs and efficient industrial recommenders. Solves the latency issue of LLM4Rec while effectively tackling the cold-start problem.