📝 Paper Summary
Recommender Systems Evaluation
LLM-as-a-Judge
RecSys Arena utilizes large language models to simulate users and perform pair-wise comparative evaluations of recommender systems, offering fine-grained feedback that aligns better with user preferences than traditional point-wise metrics.
Core Problem
Traditional offline evaluation metrics (like AUC) often fail to capture subtle differences in user satisfaction and are inconsistent with online A/B test results, while online testing is risky and slow.
Why it matters:
- Offline metrics like AUC are not sufficiently sensitive to distinguish the real quality of competitive recommender systems
- Mainstream metrics such as CTR do not fully reflect long-term user experience or satisfaction
- Existing LLM-based evaluations mostly focus on absolute point-wise scoring, which lacks the context needed for granular comparison
Concrete Example:
Two competitive recommender systems might have nearly identical AUC scores on a dataset, yet one might offer significantly more diverse or serendipitous items that a user would prefer. Standard metrics miss this nuance, whereas a pair-wise LLM judge can articulate the preference based on the user profile.
Key Novelty
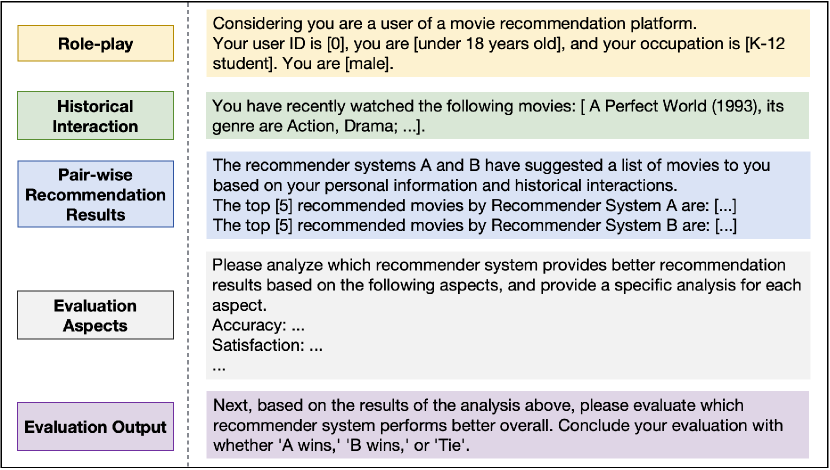
LLM-based Pair-wise Relative Evaluation for RecSys
- Instead of asking an LLM to score a single recommendation list (point-wise), the system presents two lists side-by-side to an LLM simulator playing the role of a specific user
- Leverages LLM's strong reasoning and role-play capabilities to determine a winner between two models based on user profiles and history, similar to Chatbot Arena but for recommendations
Architecture
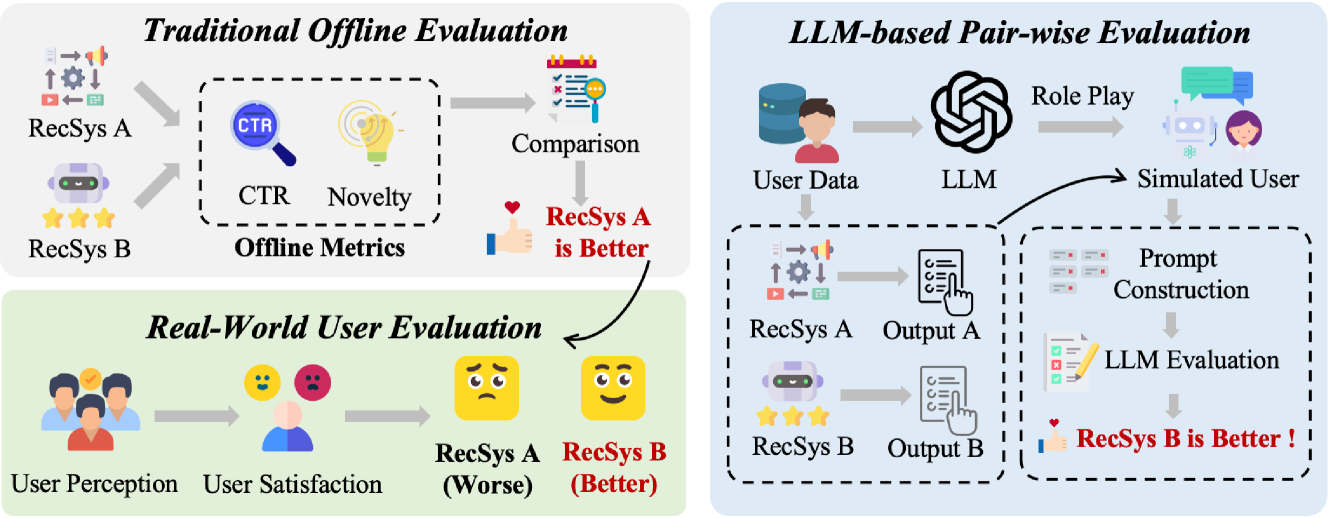
Overview of RecSys Arena methodology
Evaluation Highlights
- LLM-based pair-wise evaluation results align with trends observed in offline metrics like AUC and Diversity when comparing recommendation models
- Proposed method effectively distinguishes between recommendation algorithms that have comparable performance in terms of traditional AUC and nDCG metrics
- Evaluation on MovieLens and MIND datasets confirms that larger LLMs generally provide better evaluation effectiveness
Breakthrough Assessment
7/10
Applies the successful 'Arena' concept from NLP to RecSys. While the underlying idea of using LLMs for evaluation isn't new, the specific pair-wise framework for ranking recommendation lists addresses a key limitation of point-wise scoring.