📝 Paper Summary
Sequential Recommendation
Continual Learning / Incremental Learning
Parameter-Efficient Fine-Tuning (PEFT)
RAIE adapts to shifting user preferences by partitioning interaction history into semantic regions, each paired with a dedicated LoRA adapter that is dynamically updated or added only when drift occurs.
Core Problem
User preferences evolve over time (drift), but static LLM recommenders fail to adapt, while global fine-tuning causes catastrophic forgetting of old interests.
Why it matters:
- Global updates perturb stable preferences while trying to learn new ones (imbalanced update granularity)
- Repeated edits interfere with prior adaptations, leading to inconsistent recommendations
- Retraining massive LLM backbones for every preference shift is computationally prohibitive
Concrete Example:
A user historically likes 'Mystery' but recently shifts to 'Horror'. A static model over-recommends Mystery. A globally fine-tuned model might learn Horror but forget the long-term Mystery preference. RAIE updates only the 'Horror' region (or adds it) while keeping the 'Mystery' region's adapter intact.
Key Novelty
Region-Aware Incremental Editing (RAIE)
- Conceptualizes user history as clusters in semantic space (Knowledge Regions), each managed by a specific LoRA adapter.
- Introduces three discrete editing operations (Update, Expand, Add) to dynamically modify region boundaries based on new data confidence scores.
- Decouples stability and plasticity by routing inference to specific regional adapters, preventing new learning from overwriting established distinct preferences.
Architecture
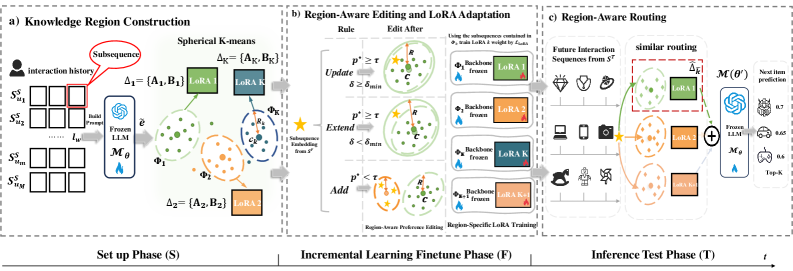
The overall RAIE architecture illustrating the three phases: Set-up (clustering), Fine-tuning (Editing + LoRA training), and Inference (Routing).
Breakthrough Assessment
7/10
Novel integration of knowledge editing concepts with continuous preference modeling. The explicit 'region' management with dedicated LoRAs is a logically sound approach to the stability-plasticity dilemma in recommendation.