📝 Paper Summary
IoT Operation Recommendation
LLM Personalization
DevPiolt adapts LLMs for smart home control by pre-training on device logs, refining preferences via conflict-based DPO, and using confidence scores to filter risky suggestions.
Core Problem
Existing recommenders fail to handle the strict sequential logic of physical devices (e.g., power on before setting mode) and struggle to filter illogical or conflicting suggestions that frustrate users.
Why it matters:
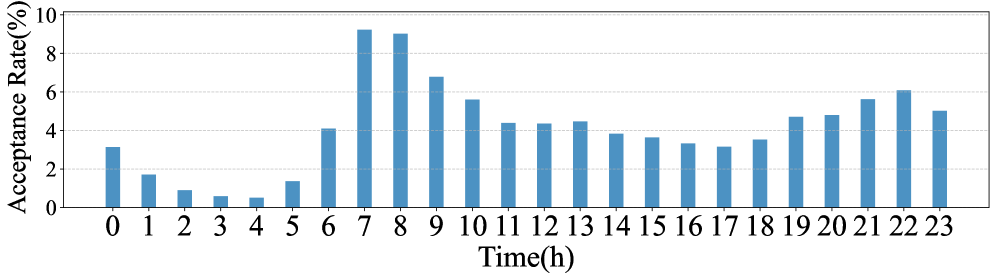
- IoT environments require precise, logical action sequences; a single bad suggestion (e.g., turning on lights at 3 AM) destroys user trust
- Users have conflicting, time-sensitive habits (e.g., curtains open in AM but closed in PM) that standard models often miss
- Suboptimal suggestions in physical spaces are more intrusive than digital content recommendations
Concrete Example:
If a user manually turns off the AC, a standard recommender might immediately suggest turning it back on based on temperature rules, creating a conflict. DevPiolt uses DPO to learn that immediate reversal is a 'negative' preference.
Key Novelty
Action-First LLM Refinement with Implicit DPO
- Action-First Generation: Forces the LLM to predict precise structured action parameters (device, mode, value) before generating the natural language description, grounding the output in valid logic
- Conflict-Aware DPO: Constructs preference pairs automatically by treating time-inappropriate or recently-reversed actions as negative samples, aligning the model without expensive human labeling
- Confidence-Based Exposure: Calculates a weighted confidence score across action attributes, suppressing any recommendation where the model is uncertain to prevent user annoyance
Architecture
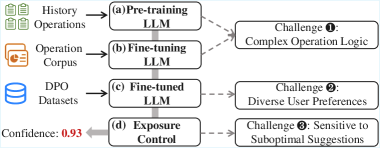
The four-stage pipeline of DevPiolt: Pre-training, Fine-tuning, Refinement (DPO), and Exposure Control.
Evaluation Highlights
- Achieved 21.6% increase in Unique Visitor (UV) device coverage in online A/B testing with 255,000 users
- Improved Page View (PV) acceptance rates by 29.1% in the Xiaomi Home app compared to the previous system
- Outperformed best baselines by 95.5% in exact match accuracy and 58.5% in loose match F1 score on offline datasets
Breakthrough Assessment
8/10
Strong practical contribution. Successfully deploys LLM-based recommendations in a massive-scale real-world IoT system (Xiaomi Home), addressing critical reliability issues via novel confidence and preference mechanisms.