📝 Paper Summary
LLM-based Recommendation
Learning to Rank
R2Rank optimizes Large Language Models for recommendation by decoupling reasoning into pointwise inferences and using a probabilistic surrogate to backpropagate listwise ranking rewards directly into the reasoning generation process.
Core Problem
LLMs suffer from position bias when ranking items directly and their standard next-token training objectives do not align with non-differentiable listwise recommendation metrics like NDCG.
Why it matters:
- Position bias breaks the permutation invariance required for robust ranking, causing models to favor items based on input order rather than relevance
- Existing methods rely on prompt engineering for reasoning but lack a mechanism to directly optimize that reasoning for recommendation utility (ranking quality)
- Conceptualizing recommendation as simple pattern matching underestimates the need for deep logical reasoning to infer latent user interests from history
Concrete Example:
When given a list of candidate items to rank, a standard LLM's output is heavily influenced by the order in which items appear in the prompt (position bias). Furthermore, if the model generates a plausible-sounding rationale that leads to a bad recommendation, standard training doesn't penalize the reasoning process based on the final ranking quality.
Key Novelty
Reasoning to Rank (R2Rank)
- Decouples recommendation into pointwise inferences where the LLM generates rationales for one item at a time, mapping these rationales to scalar scores to eliminate position bias
- employs a Plackett-Luce probabilistic surrogate to convert discrete ranking scores into a differentiable distribution, allowing listwise rewards (NDCG) to update the LLM via Reinforcement Learning
- Uses a self-reflective Supervised Fine-Tuning (SFT) stage initialized with data synthesized by a reasoning model (DeepSeek-R1) to teach the model a 'verify-then-conclude' reasoning pattern
Architecture
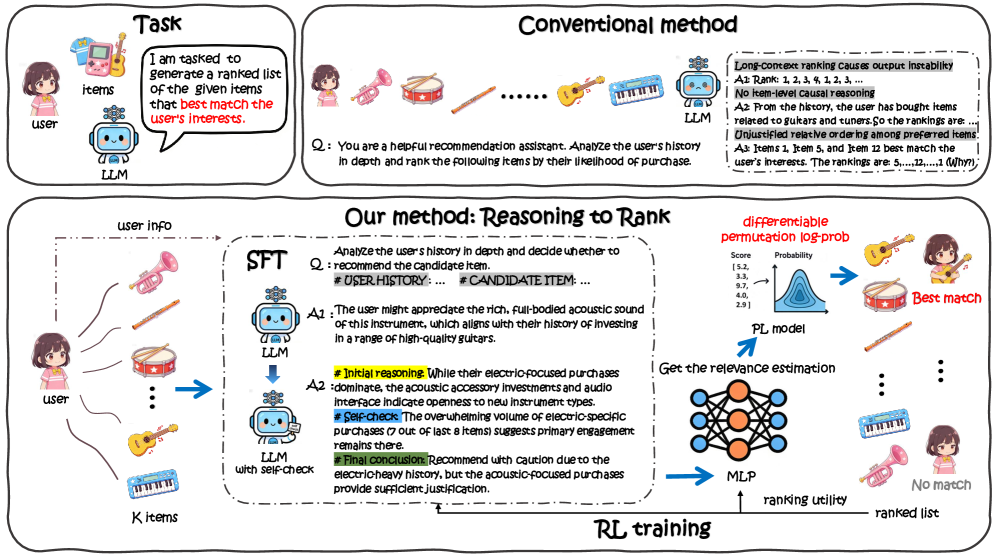
The R2Rank framework pipeline illustrating the separation of item-level reasoning from listwise ranking
Breakthrough Assessment
7/10
Addresses critical bottlenecks in LLM recommendation (position bias and non-differentiable ranking metrics) with a theoretically sound RL approach, though the base model architecture is standard.