📊 Experiments & Results
Evaluation Setup
Few-shot and Zero-shot prediction on tabular e-commerce data
Benchmarks:
- Customer Response Prediction (Binary Classification)
- Brand Recommendation (Top-K Ranking (Selection from 17 brands))
Metrics:
- F1 score
- Precision
- Recall
- Expected CTR
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| AdaRec significantly outperforms both traditional ML and LLM baselines in few-shot settings. | ||||
| Customer Response Prediction (5-shot) | F1 | 86.67 | 94.33 | +7.66 |
| Brand Recommendation (5-shot) | CTR | 9.0 | 10.3 | +1.3 |
| Narrative profiling demonstrates massive gains over expert profiling in zero-shot scenarios, proving better adaptability. | ||||
| Customer Response Prediction (0-shot) | F1 | 55.58 | 74.13 | +18.55 |
| The model shows strong cross-task generalization, retaining performance when fine-tuned on one task and tested on another. | ||||
| Brand Recommendation (5-shot) | CTR | 9.7 | 9.7 | 0.0 |
Experiment Figures

Comparison of Expert Profiling vs. Narrative Profiling text outputs
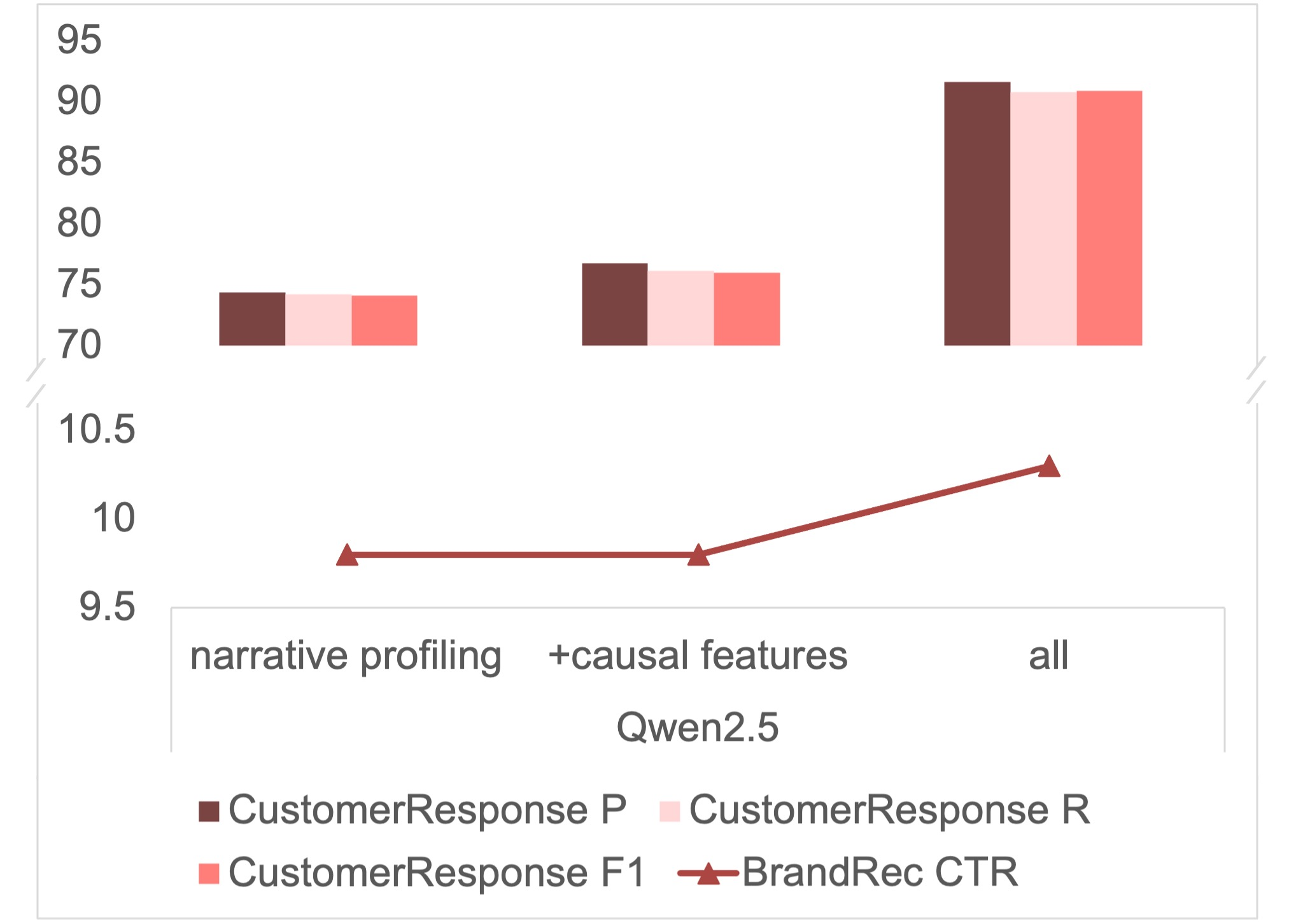
Ablation study of different components (Narrative only vs +Causal vs +History)
Main Takeaways
- AdaRec outperforms LightGBM by ~8% in few-shot settings, despite LightGBM seeing 1M+ samples, demonstrating extreme data efficiency
- Narrative profiling is far more robust than expert profiling in zero-shot settings (+19%), as it adapts to data distributions automatically
- The dual-channel architecture is robust: ablation shows removing historical patterns causes the largest drop, while causal features provide moderate but essential gains for precision
- Cross-task evaluation shows the learned representations are generalizable, eliminating the need for task-specific retraining