📝 Paper Summary
Recommender Systems Benchmarking
Sequential Recommendation
Privacy-Preserving Data Construction
ORBIT standardizes recommender system evaluation with consistent public benchmarks and ClueWeb-Reco, a hidden test set constructed by soft-matching real user browsing histories to public webpages to preserve privacy.
Core Problem
Existing recommendation datasets rely on unrealistic proxies like reviews rather than actual browsing behavior, lack explicit user consent, and suffer from inconsistent evaluation splits that hinder reproducibility.
Why it matters:
- Reviewing behavior (1-2% of interactions) is far sparser than and distinct from viewing behavior, meaning current benchmarks fail to model real user interests
- Inconsistent data splits and metric definitions across studies make it impossible to fairly compare state-of-the-art models
- Releasing real user browsing history for realistic evaluation poses severe privacy and legal risks regarding Personally Identifiable Information (PII)
Concrete Example:
A user's browsing history might include sensitive local school applications or health searches. Releasing this raw sequence violates privacy (PII leakage), but synthetic data generated by LLMs fails to capture the complex, rapid topic shifts of real human surfing.
Key Novelty
Privacy-Preserving Soft-Matching for Realistic Evaluation Data
- Collects real browsing history with consent, then replaces each private URL with the most semantically similar public webpage from the ClueWeb22 corpus using dense retrieval
- Removes exact URL matches to ensure the dataset is fully synthetic while preserving the semantic trajectory and domain distribution of real user behavior
Architecture
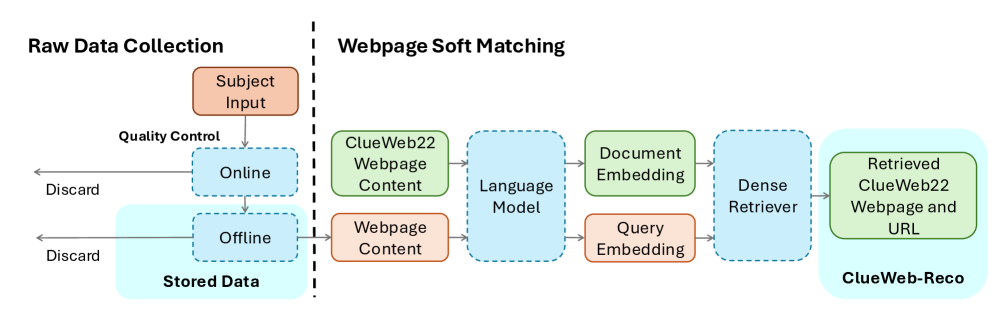
The ClueWeb-Reco dataset construction pipeline, illustrating how private user history is transformed into a public dataset.
Evaluation Highlights
- Constructed ClueWeb-Reco from 41,760 raw browsing records, resulting in 1,024 high-quality validation/test sessions after filtering
- Achieved moderate inter-annotator agreement (Cohen's kappa 0.372) on the semantic relevance of soft-matched pages, confirming preservation of user intent
- Maintained domain consistency: Top domains in the synthetic ClueWeb-Reco dataset (e.g., YouTube) closely mirror the rank distribution of the raw private data
Breakthrough Assessment
8/10
Addresses a critical crisis in recommendation research (reproducibility and realism) with a novel, privacy-safe method for releasing 'real' user behavior. The hidden test set paradigm is a significant maturity step for the field.