📝 Paper Summary
Collaborative Filtering
LLM-enhanced Recommendation
CoReLLa integrates efficient conventional recommenders (CRMs) for easy tasks and reasoning-capable LLMs for hard tasks using an entropy-based routing mechanism and layer-wise alignment training.
Core Problem
Existing methods use either LLMs or CRMs exclusively, or blindly combine them, failing to leverage their distinct strengths: CRMs excel at collaborative signals (easy samples) while LLMs excel at semantic reasoning (hard samples).
Why it matters:
- CRMs struggle with low-confidence scenarios like long-tail items or noisy data where semantic reasoning is needed
- LLMs are computationally expensive and struggle to capture collaborative signals without massive training data
- Training models independently leads to 'decision boundary shifts,' causing inconsistencies when combining their predictions
Concrete Example:
A CRM might assign low confidence to a long-tail book due to sparse interaction data (high entropy). A standalone LLM might misinterpret user history without collaborative signals. CoReLLa detects the CRM's uncertainty and routes this specific 'hard' sample to the LLM, which uses semantic knowledge to predict the click.
Key Novelty
Collaborative Recommendation with Conventional Recommender and Large Language Model (CoReLLa)
- System 1 vs. System 2 architecture: Uses the fast CRM (System 1) for most queries and activates the slow, reasoning-heavy LLM (System 2) only when the CRM is uncertain
- Entropy-based routing: Dynamically determines sample difficulty based on the entropy of the CRM's prediction probability
- Layer-wise alignment: Syncs the internal representations of the CRM and LLM during joint training to prevent decision boundary shifts
Architecture
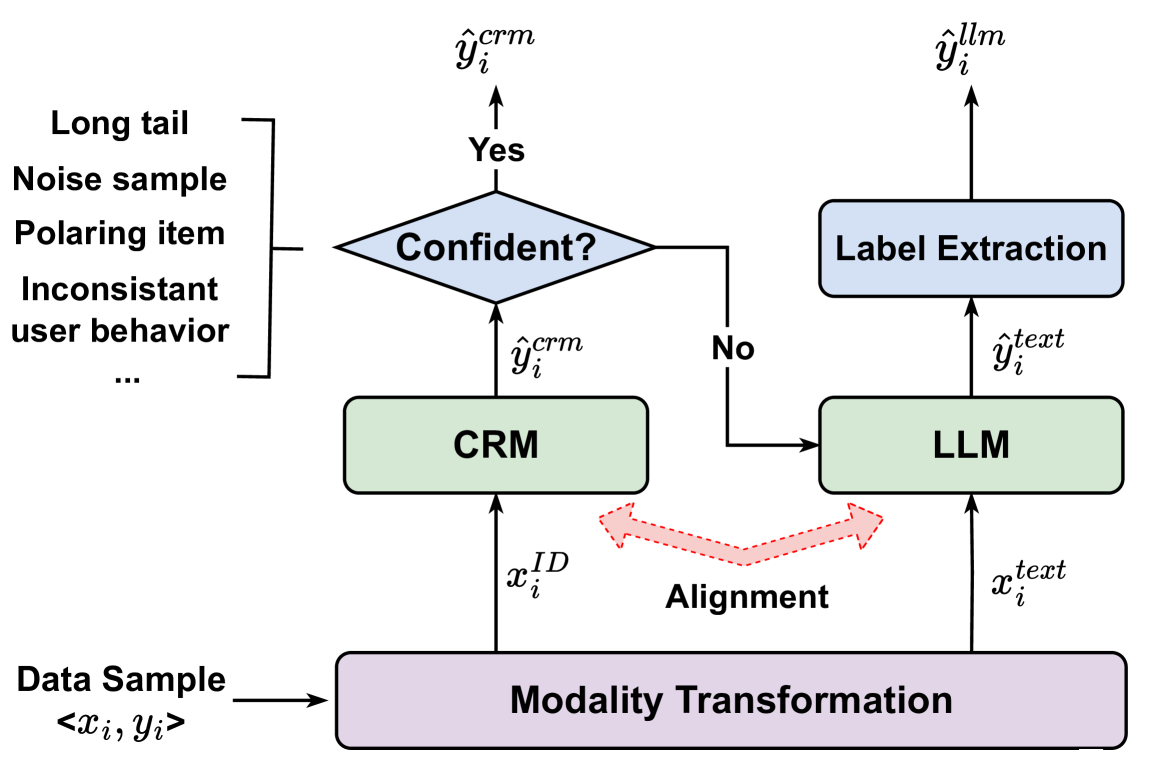
The CoReLLa framework showing the dual-path inference (CRM vs LLM) and the joint training alignment strategy.
Evaluation Highlights
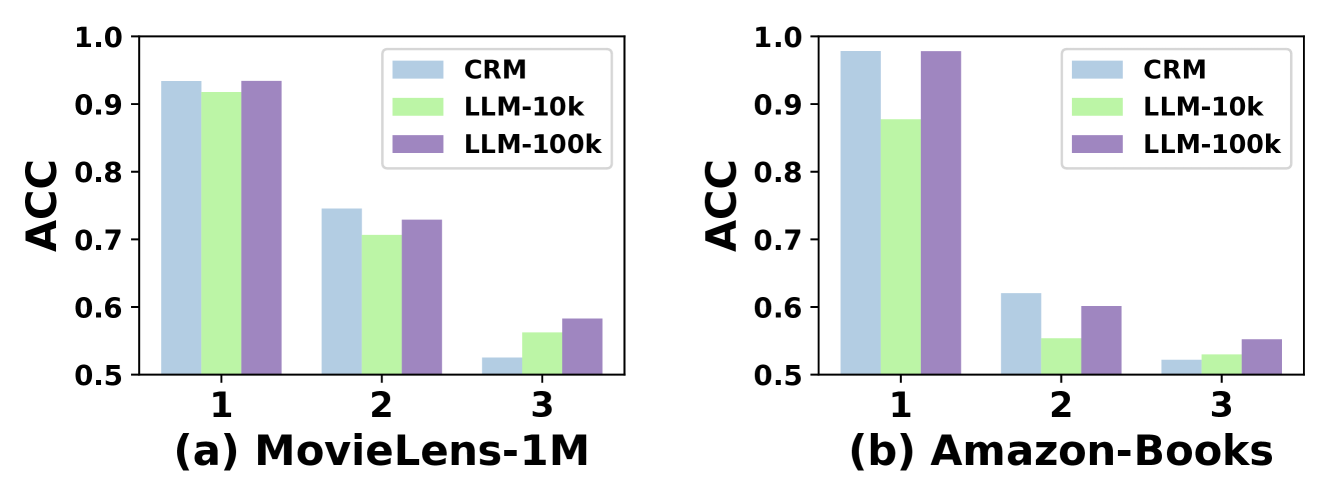
- Achieves 1.38% reduction in LogLoss and 1.03% increase in Accuracy on Amazon-Books dataset compared to state-of-the-art baselines
- Improves AUC by 0.72% and Accuracy by 1.08% on MovieLens-1M compared to the best performing baselines
- Significantly outperforms pure LLM-based methods (like TALLRec) and pure CRM methods (like DCNv2) by effectively combining their strengths
Breakthrough Assessment
7/10
Offers a pragmatic 'best of both worlds' approach (speed vs. reasoning) with a solid theoretical grounding in System 1/2 thinking, though the core components (DCN, LLaMA) are standard.