📝 Paper Summary
Adversarial Attacks on Recommender Systems
LLM-based Recommendation Security
Attackers can significantly boost a target item's exposure in LLM-based recommender systems by imperceptibly altering its textual content (titles) during testing, without needing to influence model training.
Core Problem
LLM-based recommender systems heavily rely on textual content, creating a new vulnerability where slight text modifications can manipulate rankings.
Why it matters:
- Malicious actors can unfairly promote low-quality products or misinformation without detection.
- Traditional shilling attacks (injecting fake user interactions) are less effective against LLM-based models and are easier to detect due to performance degradation.
- Current security research overlooks the specific vulnerabilities introduced by the semantic sensitivity of LLMs in recommendation contexts.
Concrete Example:
An attacker wants to promote a specific item. By using a black-box attack tool (like TextFooler) to subtly change the item's title—swapping synonyms or inserting invisible characters—the LLM recommender (e.g., RecFormer) suddenly ranks it in the top-50 for many users, whereas the original title was ignored.
Key Novelty
Test-Phase Textual Adversarial Attack on RS
- Exploits the semantic sensitivity of LLMs: unlike ID-based models, LLM-based recommenders react strongly to textual phrasing.
- Requires zero training data poisoning: the attack happens entirely at inference time by modifying the item's metadata (title).
- Achieves high stealthiness: the modified text remains human-readable and relevant, and the system's overall accuracy metrics (Recall, NDCG) do not drop, masking the attack.
Architecture
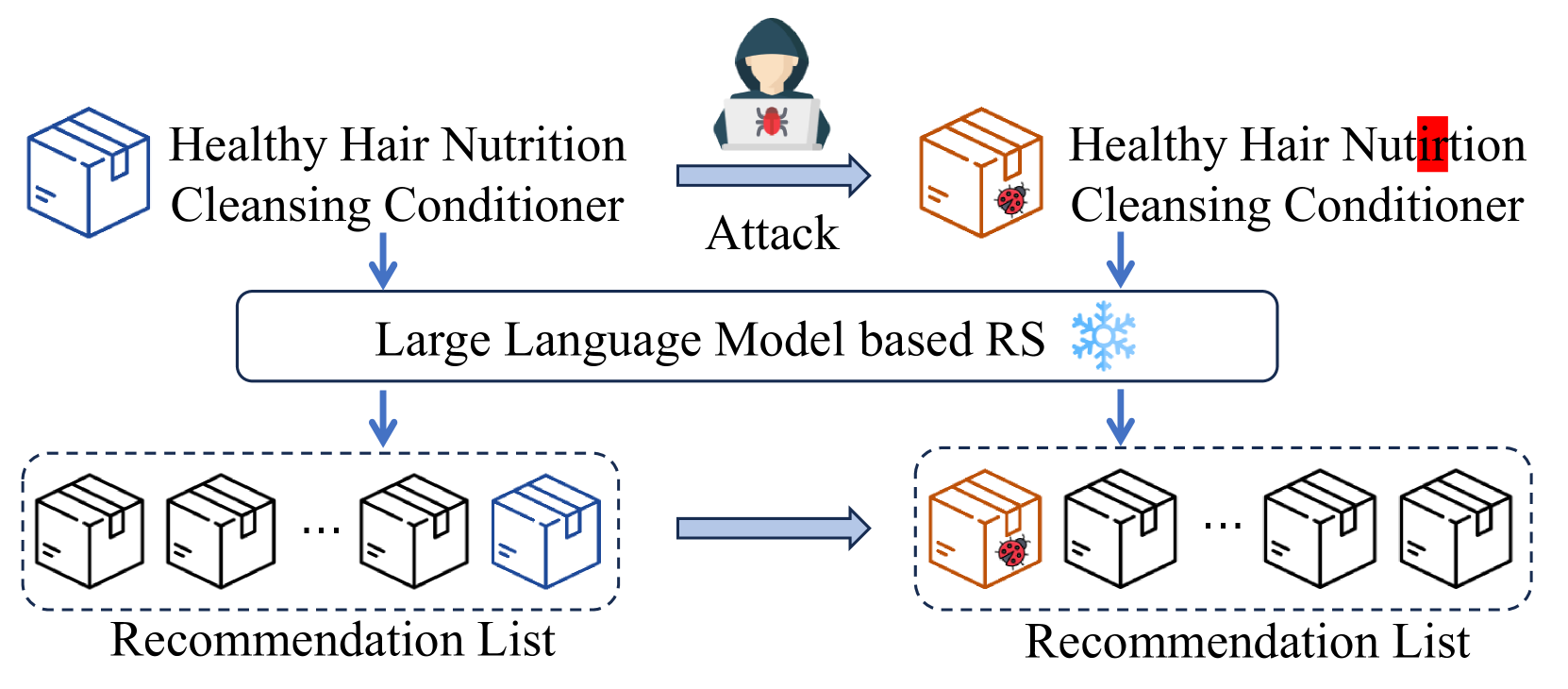
The iterative Black-Box Text Attack procedure applied to recommendation items.
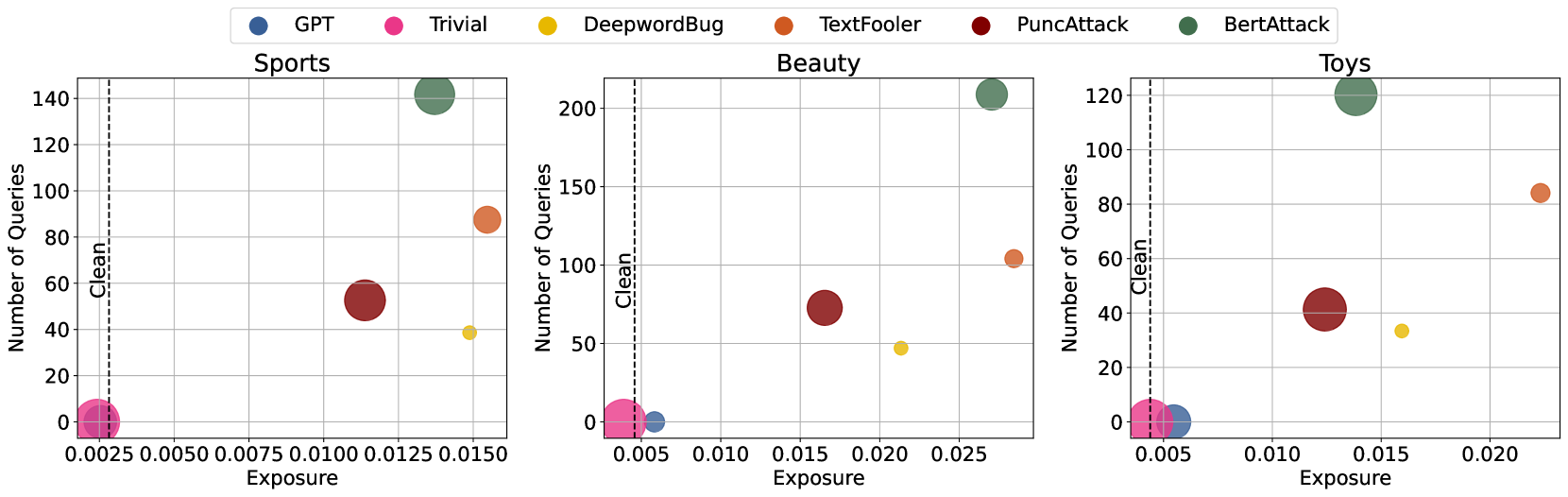
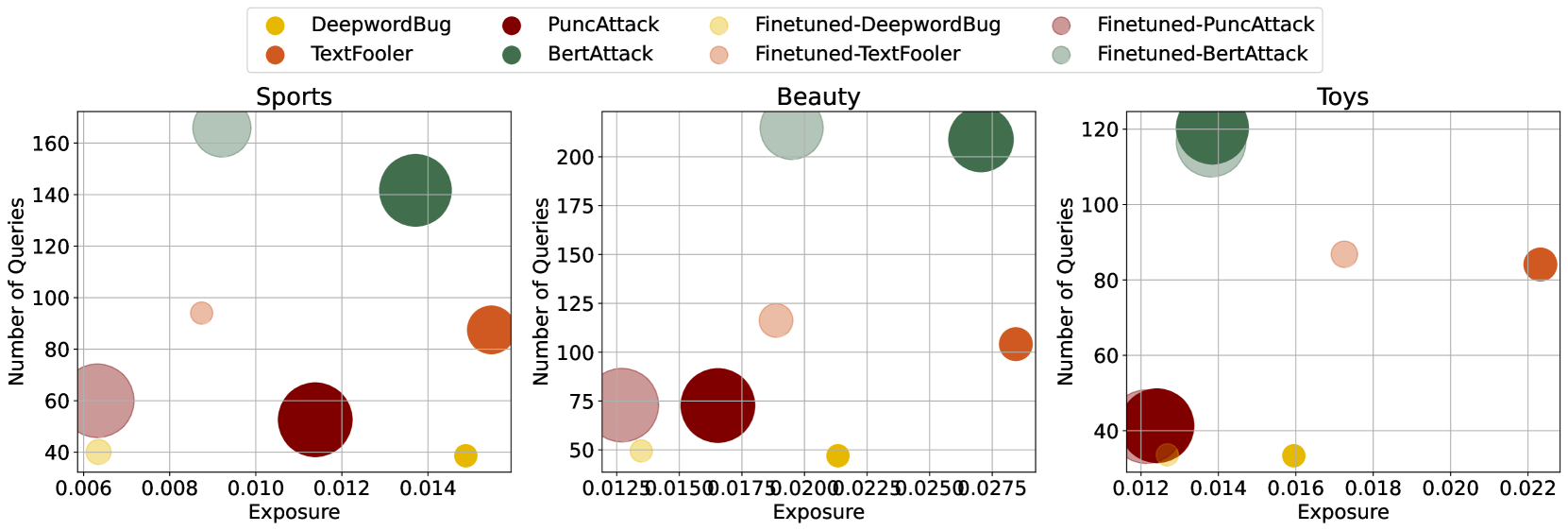
Evaluation Highlights
- On RecFormer (Beauty dataset), the 'BertAttack' method increases target item exposure rate from ~0.2% to ~20%, a 100x increase.
- Simple GPT-based rewriting of titles increases purchasing propensity on the P5 model from ~0.4 to ~0.7 on the Toys dataset.
- Attacks maintain high stealthiness: Overall Recall@50 on RecFormer drops negligibly (from 0.0381 to 0.0379) even when 10% of items are attacked.
Breakthrough Assessment
8/10
First work to systematically demonstrate the vulnerability of LLM-based recommenders to textual attacks. The results are striking (huge exposure gains) and the stealthiness aspect is critical for real-world security.