📝 Paper Summary
Explainable Recommendation
Prompt Learning
Multi-task Learning
The paper proposes a multi-task framework that generates explainable recommendations by using continuous vector prompts for user/item IDs and automatically balancing rating prediction and explanation generation losses via uncertainty weighting.
Core Problem
Refining LLMs for explainable recommendations is computationally expensive, and using discrete text prompts for user/item IDs often loses implicit feature information embedded in those IDs.
Why it matters:
- Fine-tuning massive LLMs (like GPT-2/3) for every recommendation task is impractical due to resource constraints
- Discrete prompts (translating IDs to words) can be irreversible or lossy, failing to capture the full latent representation of users and items
- Manually tuning loss weights in multi-task learning (rating prediction + explanation) is complex and time-consuming
Concrete Example:
Representing an item solely by discrete feature words like {bathroom, subway, gym} loses the unique identity of the specific item compared to using its ID vector. Simply inputting raw ID strings to an LLM is also ineffective as the model lacks context for them.
Key Novelty
Continuous Prompt Learning with Uncertainty-Weighted Multi-Tasking
- Treats user and item IDs as special tokens mapped to continuous vectors (soft prompts) rather than discrete natural language words, allowing the LLM to optimize these representations directly
- Uses a homoskedastic uncertainty weighting strategy to dynamically learn the optimal balance between the rating prediction loss and the explanation generation loss during training
Architecture
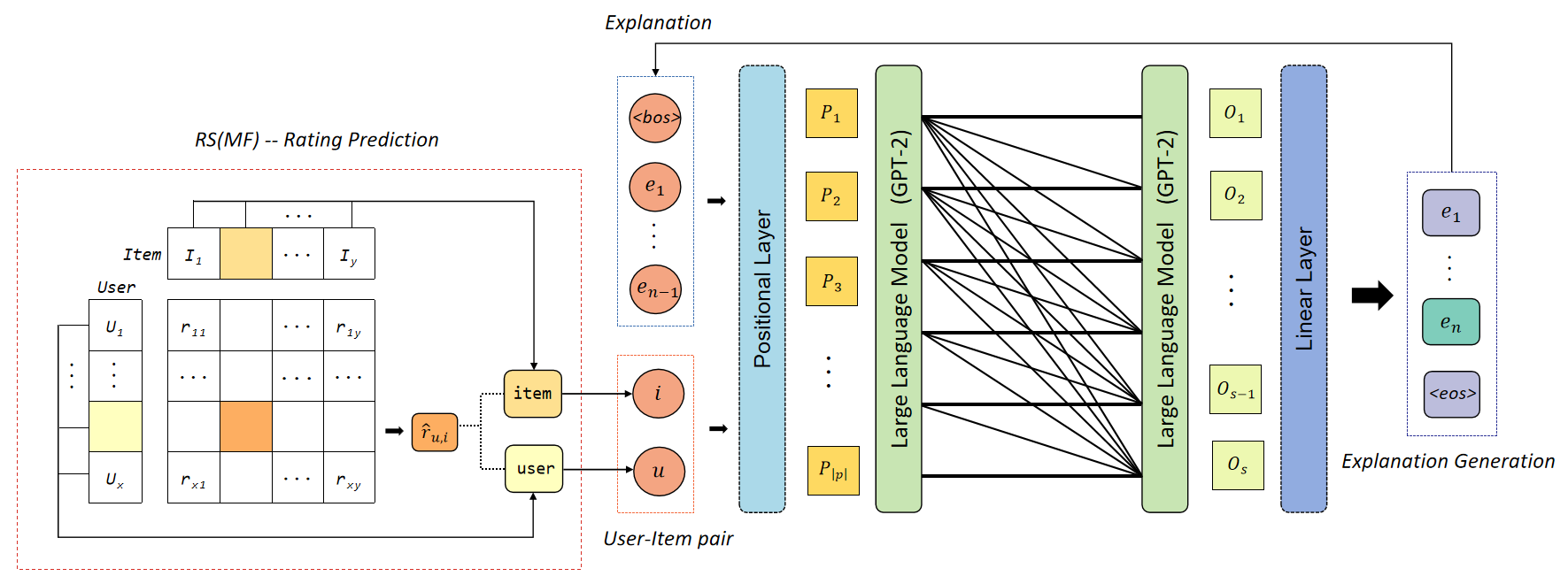
The overall framework of the Uncertainty-Aware Explainable Recommendation model.
Evaluation Highlights
- Achieves 1.59 Diversity (DIV) on Yelp dataset, outperforming baselines in explanation variety
- Reaches 0.57 Unique Sentence Ratio (USR) on TripAdvisor, indicating generated explanations are less repetitive
- Attains 0.41 Feature Coverage Ratio (FCR) on Amazon dataset, showing better inclusion of relevant item features in explanations
Breakthrough Assessment
4/10
Applies existing concepts (continuous prompts, uncertainty weighting) effectively to the specific niche of explainable recommendation with GPT-2. Good incremental improvement but not a fundamental architectural shift.