📝 Paper Summary
LLM for Recommendation
Knowledge Augmentation
Click-Through Rate (CTR) Prediction
KAR augments recommender systems by using large language models to generate user preference reasoning and item factual knowledge, which are then compressed by a hybrid-expert adaptor for efficient deployment.
Core Problem
Classical recommender systems are 'insulated' within closed domains, lacking external world knowledge, while direct use of LLMs suffers from high latency and a 'compositional gap' where they fail at the specific task of ranking items.
Why it matters:
- Closed systems miss contextual clues (e.g., seasonal preferences or external events) that are obvious to humans but absent in ID-based data.
- Directly deploying LLMs in industrial systems is impractical due to strict latency requirements (usually <100ms) and cost.
- LLMs struggle with the specific 'compositional' task of recommendation despite understanding the sub-problems, leading to suboptimal accuracy compared to specialized models.
Concrete Example:
A user might watch holiday movies during Christmas. A classical ID-based model only sees a behavior pattern, but an LLM can explicitly reason 'User is interested in holiday themes due to the season.' Current systems miss this explicit reasoning.
Key Novelty
Open-World Knowledge Augmented Recommendation (KAR)
- Factorization Prompting: Breaks the recommendation problem into generating 'reasoning knowledge' (user preferences) and 'factual knowledge' (item details) separately to bypass the LLM's compositional weakness.
- Hybrid-Expert Adaptor: A specialized neural module that transforms verbose, high-dimensional LLM outputs into compact dense vectors compatible with traditional recommenders, filtering noise via mixture-of-experts.
- Pre-storage Strategy: Decouples LLM generation from real-time inference by generating and caching knowledge offline, eliminating inference latency.
Architecture
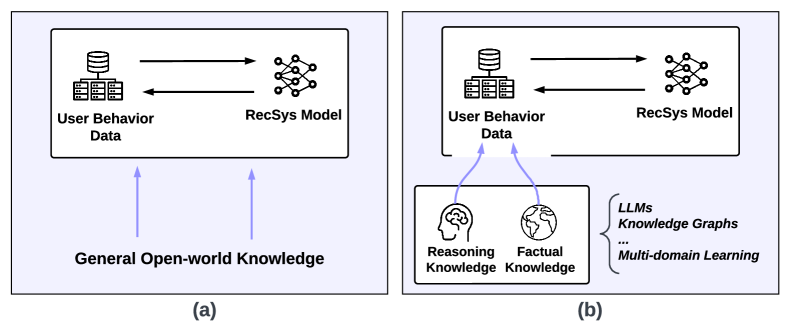
The transition from closed-world systems (learning only from domain data) to open-world systems (acquiring reasoning/factual knowledge from LLMs), and the KAR pipeline transforming this knowledge into vectors.
Evaluation Highlights
- +7% improvement in online A/B testing on Huawei's news recommendation platform compared to the production baseline.
- +1.7% improvement in online A/B testing on Huawei's music recommendation platform compared to the production baseline.
- Significantly outperforms state-of-the-art baselines on public datasets (results described qualitatively in text as numeric tables were not in the provided snippet).
Breakthrough Assessment
8/10
Achieves a rare successful deployment of LLM-augmented recommendation in a large-scale industrial setting (Huawei) with significant online metrics, solving the critical latency bottleneck.