📝 Paper Summary
LLM-based Recommendation
Preference Optimization
NAPO enhances LLM-based recommendation by efficiently sharing negative samples within batches and dynamically adjusting optimization margins based on negative sample confidence.
Core Problem
Standard DPO-based recommenders struggle to efficiently utilize large numbers of negative samples due to high computational costs, and they treat all negative samples as equally informative, ignoring varying confidence levels.
Why it matters:
- Expanding the negative sample pool is crucial for improving ranking accuracy and reducing popularity bias in recommenders
- Naive integration of more negatives significantly increases training time and memory usage because LLMs must decode each sample separately
- Treating all negatives equally can lead to over-penalizing semantically similar items (false negatives) or under-emphasizing truly irrelevant ones, destabilizing optimization
Concrete Example:
A recommender might treat a randomly sampled 'science fiction' movie as a negative for a 'romantic comedy' user. However, if that random sample is actually a popular movie the user might like (a false negative), pushing it away with a standard fixed margin hurts model accuracy. Standard methods lack the nuance to adjust the penalty based on how likely the item is to be a true negative.
Key Novelty
Negative-Aware Preference Optimization (NAPO)
- In-batch negative sharing: reuses the computed log-probabilities of negative items from other sequences in the same batch, filtering them by user similarity to ensure relevance without extra decoding
- Dynamic reward margin: adjusts the optimization margin based on a confidence score from a lightweight auxiliary model; high-confidence negatives get a larger margin, while uncertain ones get a smaller margin to prevent false negative collisions
Architecture
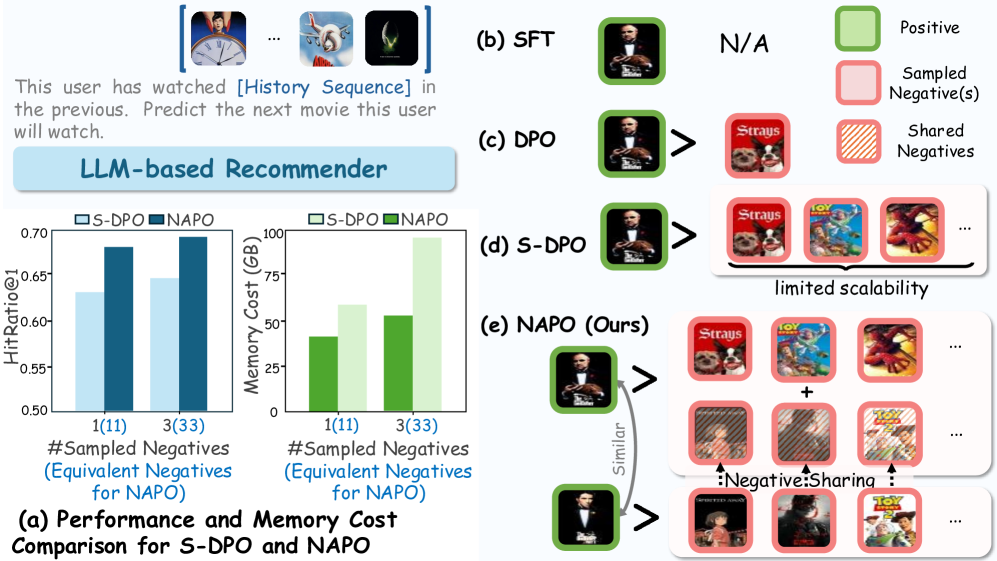
Conceptual comparison of negative sampling strategies. Figure 1 likely shows the trade-off between accuracy and cost, and the dynamic margin concept. Figure 2 illustrates the in-batch sharing mechanism.
Evaluation Highlights
- Outperforms existing methods by roughly 13% in recommendation performance across three public datasets (Goodreads, LastFM, Steam)
- Significantly reduces popularity bias compared to baselines while maintaining high accuracy
- Achieves these gains without increasing memory or computational overhead by leveraging shared in-batch negatives
Breakthrough Assessment
7/10
Solid technical improvements in efficiency and effectiveness for LLM-based recommendation. The in-batch sharing for generative models addresses a specific bottleneck, though the core concept of negative sampling is well-trodden.