📝 Paper Summary
Narrative-Driven Recommendation (NDR)
Data Augmentation with LLMs
Dense Retrieval
Mint repurposes historical user-item interaction data by prompting LLMs to generate synthetic narrative queries, creating training data for efficient retrieval models that outperform baselines without human-labeled examples.
Core Problem
Narrative-driven recommendation (NDR) lacks abundant training data because standard datasets only contain user-item interactions (ratings/reviews), not the verbose, context-rich natural language queries users actually write.
Why it matters:
- Users increasingly use conversational interfaces to solicit recommendations with complex constraints (e.g., 'quiet place for study with cheap coffee'), which keyword search handles poorly.
- Existing recommendation datasets lack the narrative query side of the input/output pair, forcing systems to rely on ineffective zero-shot methods or scarce manual data.
- Deploying large LLMs for direct inference is expensive and slow; training smaller, specialized models is preferable but requires data that doesn't exist.
Concrete Example:
A traveler posts: 'I'm looking for a dinner spot in Boston that is kid-friendly, has outdoor seating, and isn't too expensive.' Standard collaborative filtering uses ID pairs and misses the semantic constraints. Zero-shot LLMs can answer but are costly. Mint synthesizes this query from the user's past positive reviews to train a dedicated retriever.
Key Novelty
Mint (Data Augmentation with Interaction Narratives)
- Inverts the standard recommendation paradigm: instead of predicting items from a user profile, it uses an LLM to hallucinate a plausible narrative query *given* the items a user liked.
- Applies a 'filtering' step using a smaller language model to check the likelihood of the generated query against specific items, removing noise before training.
- Distills the knowledge of a massive, expensive LLM (175B) into a small, efficient bi-encoder (110M) via this synthetic dataset generation.
Architecture
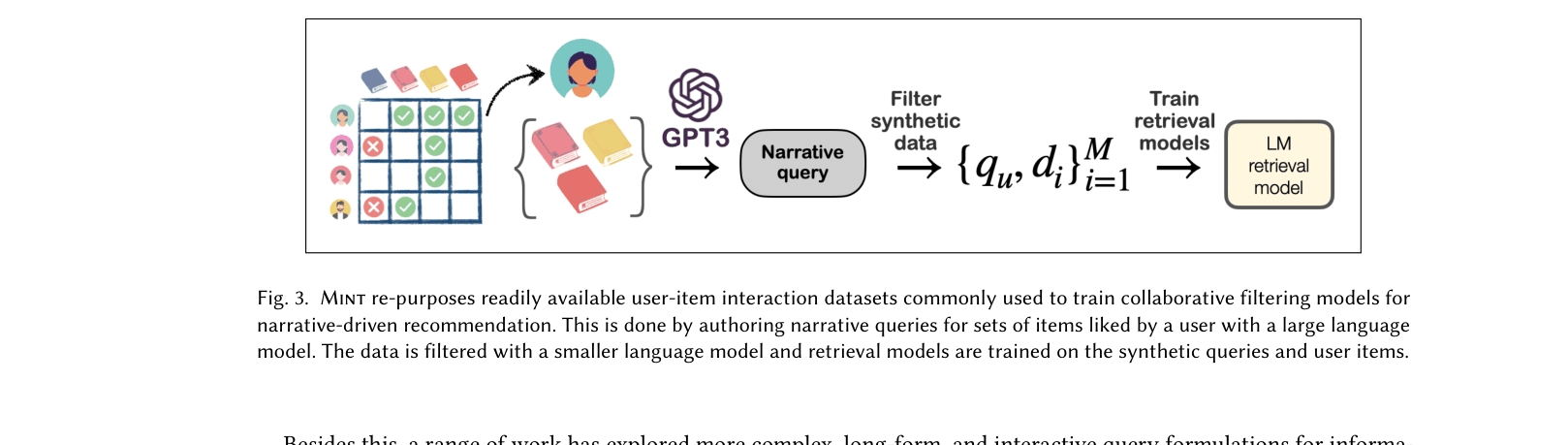
The complete workflow for creating the Mint retrieval system, from data augmentation to model training.
Evaluation Highlights
- BiEnc-Mint (110M params) outperforms the unsupervised BM25 baseline by +30% on NDCG@5 (0.3489 vs 0.2682) on the Pointrec dataset.
- Small-model BiEnc-Mint achieves statistical parity with a massive 175B Grounded LLM baseline (0.3489 vs 0.3558 NDCG@5) while being orders of magnitude more efficient.
- Cross-Encoder Mint outperforms standard bi-encoder baselines (like Contriever) by over 27% on NDCG@5 (0.3725 vs 0.2924).
Breakthrough Assessment
7/10
Clever and practical application of LLMs for data augmentation in a data-scarce domain (NDR). Matches huge model performance with small models. Limited by evaluation on a single dataset.