📝 Paper Summary
LLM-based Recommendation
Fairness in Recommender Systems
UP5 achieves counterfactually fair recommendations by learning adversarial soft prompts that remove sensitive user attributes from input embeddings while preserving recommendation utility.
Core Problem
Large Language Models (LLMs) used for recommendation inadvertently capture and use sensitive user attributes (e.g., gender, age) even when not explicitly prompted, leading to unfair recommendations.
Why it matters:
- LLM-based recommenders implicitly infer sensitive attributes from interaction history, perpetuating societal stereotypes
- Users lack control over which personal attributes influence the recommendations they receive
- Traditional fairness methods for ID-based recommenders (like altering user embeddings) do not transfer to LLM architectures where user info is textual/token-based
Concrete Example:
An elderly user might want movie recommendations based on their taste, not their age (e.g., wanting to see modern movies rather than just classics). Standard LLM recommenders might infer 'elderly' from history and stereotype the output, denying the user's preference for fairness regarding age.
Key Novelty
Counterfactually-Fair-Prompt (CFP) via Adversarial Learning
- Uses a trainable soft prompt prefix acting as a 'filter' to mask sensitive information from the LLM's internal representations
- Optimized via adversarial learning: a discriminator tries to predict the sensitive attribute from the embeddings, while the prompt is trained to fool the discriminator and maximize recommendation accuracy
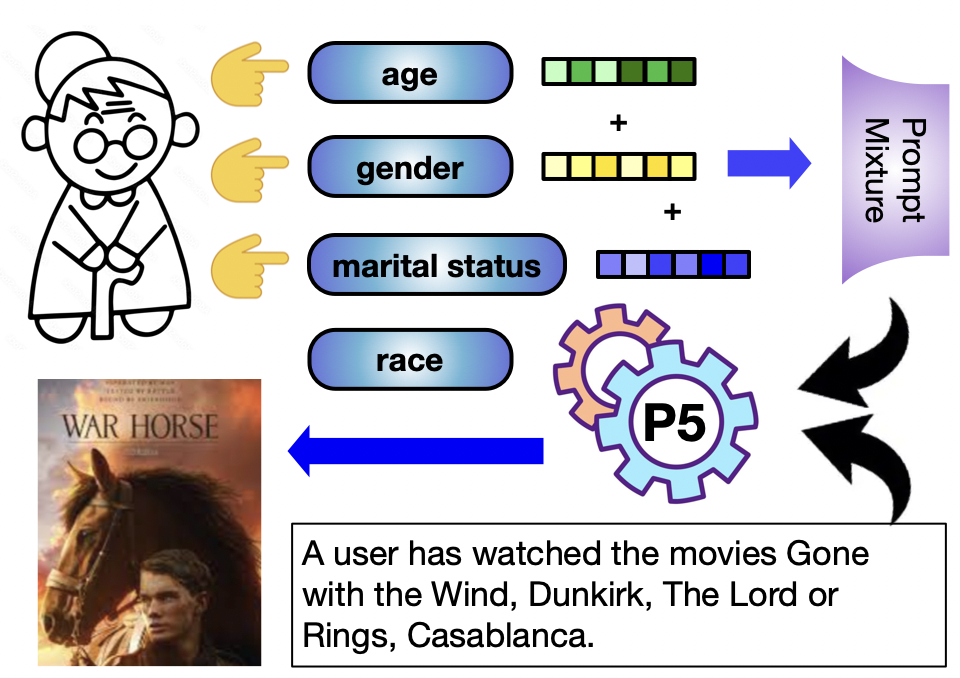
- Introduces a Prompt Mixture (PM) module that combines single-attribute fair prompts to handle multiple sensitive attributes simultaneously without training exponential combinations
Architecture
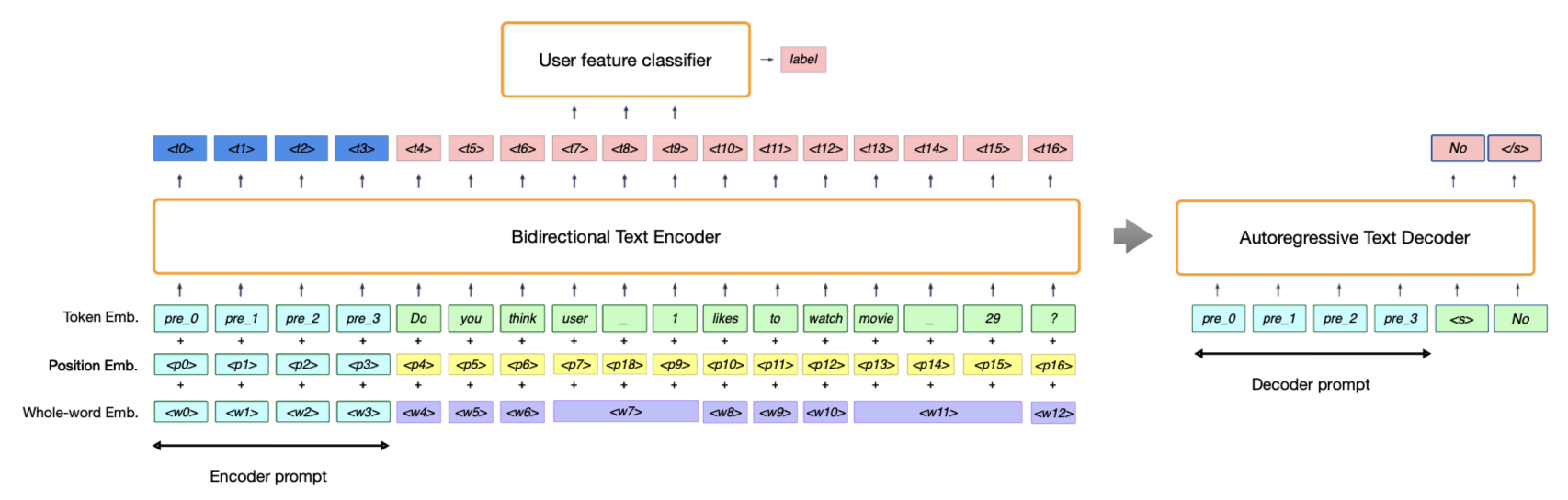
The architecture of the UP5 framework showing the adversarial training loop.
Evaluation Highlights
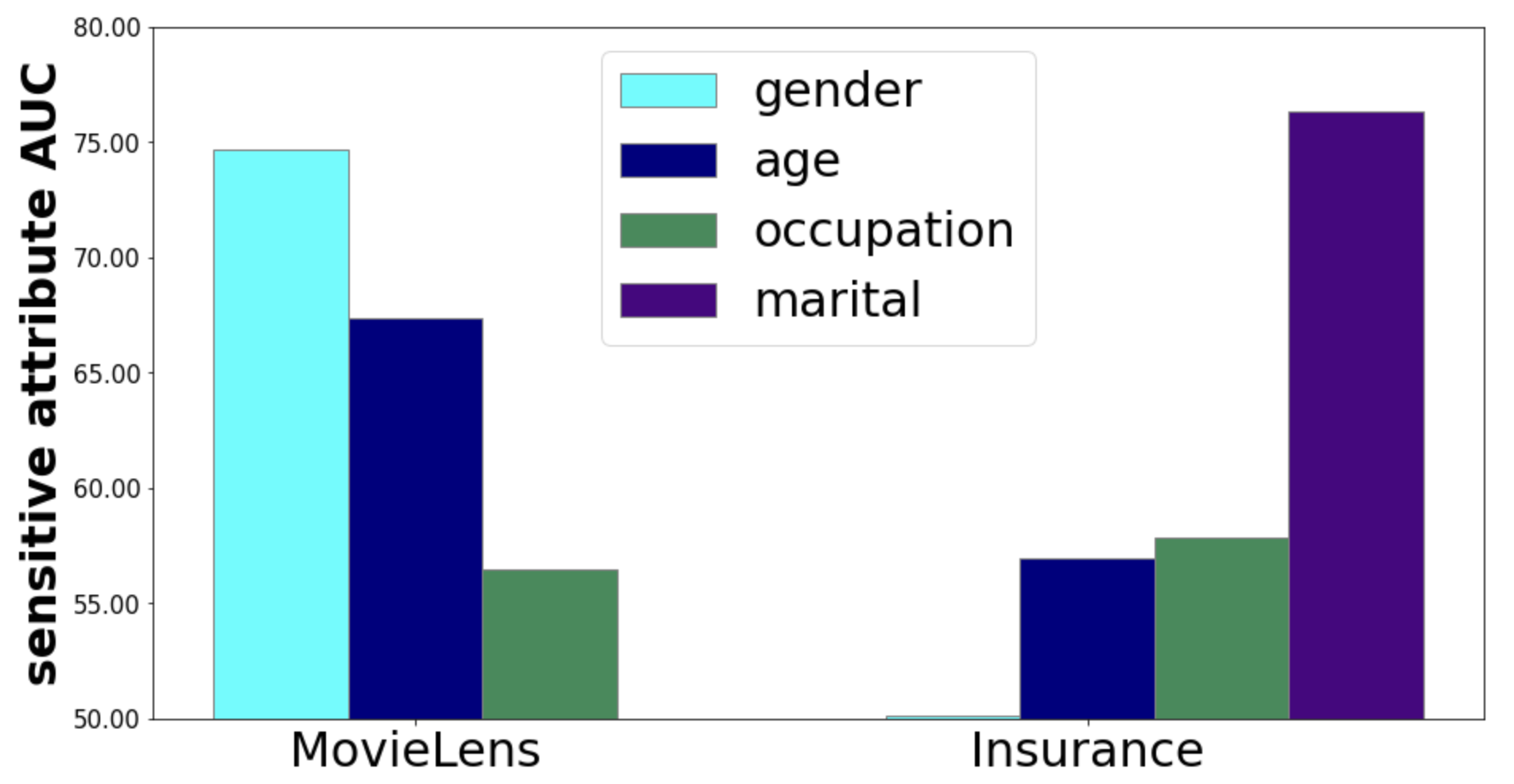
- Achieves higher Hit@1 than standard P5 baseline on MovieLens-1M (direct task) while reducing gender prediction AUC from ~0.70 to ~0.50 (random guess)
- Maintains fairness (AUC near 0.5) for multiple simultaneous attributes (gender+age) using the Prompt Mixture module without retraining from scratch
- Outperforms fairness baselines (like parameter-inefficient fine-tuning methods) in both utility (Hit@K) and fairness metrics (Attribute Prediction AUC)
Breakthrough Assessment
7/10
Effective adaptation of adversarial removal of sensitive attributes to the prompt tuning paradigm. The Prompt Mixture mechanism is a practical solution for combinatorial fairness constraints.