📝 Paper Summary
LLM for Recommendation
Benchmarking Frameworks
LLMRec benchmarks LLMs on five recommendation tasks, revealing that while they struggle with accuracy-based tasks compared to traditional models, they excel at generation tasks and benefit significantly from instruction tuning.
Core Problem
LLMs have shown prowess in NLP, but their application to Recommendation Systems (RS) is underexplored, particularly regarding whether their general knowledge translates to domain-specific accuracy and valid output formatting.
Why it matters:
- Traditional Deep Learning RS are task-specific and lack generalization, requiring massive in-domain data.
- It is unclear if off-the-shelf LLMs can replace or augment specialized RS models given the modality gap between text and user-item interactions.
- Smaller LLMs often fail to generate valid, parseable outputs for recommendation metrics without specific adaptation.
Concrete Example:
In a rating prediction task, a standard LLM might output a verbose text explanation instead of a specific number (1-5), or hallucinate item titles in sequential recommendation, making it impossible to calculate metrics like RMSE or Hit Ratio.
Key Novelty
Unified LLM-based Recommendation Benchmark (LLMRec)
- Establishes a standardized framework converting five heterogeneous recommendation tasks (rating, sequential, direct, explanation, summary) into natural language prompts.
- Compares both zero-shot (off-the-shelf) and Supervised Fine-Tuning (SFT) paradigms to quantify the 'alignment gap' between general LLM capabilities and specific recommendation needs.
Architecture
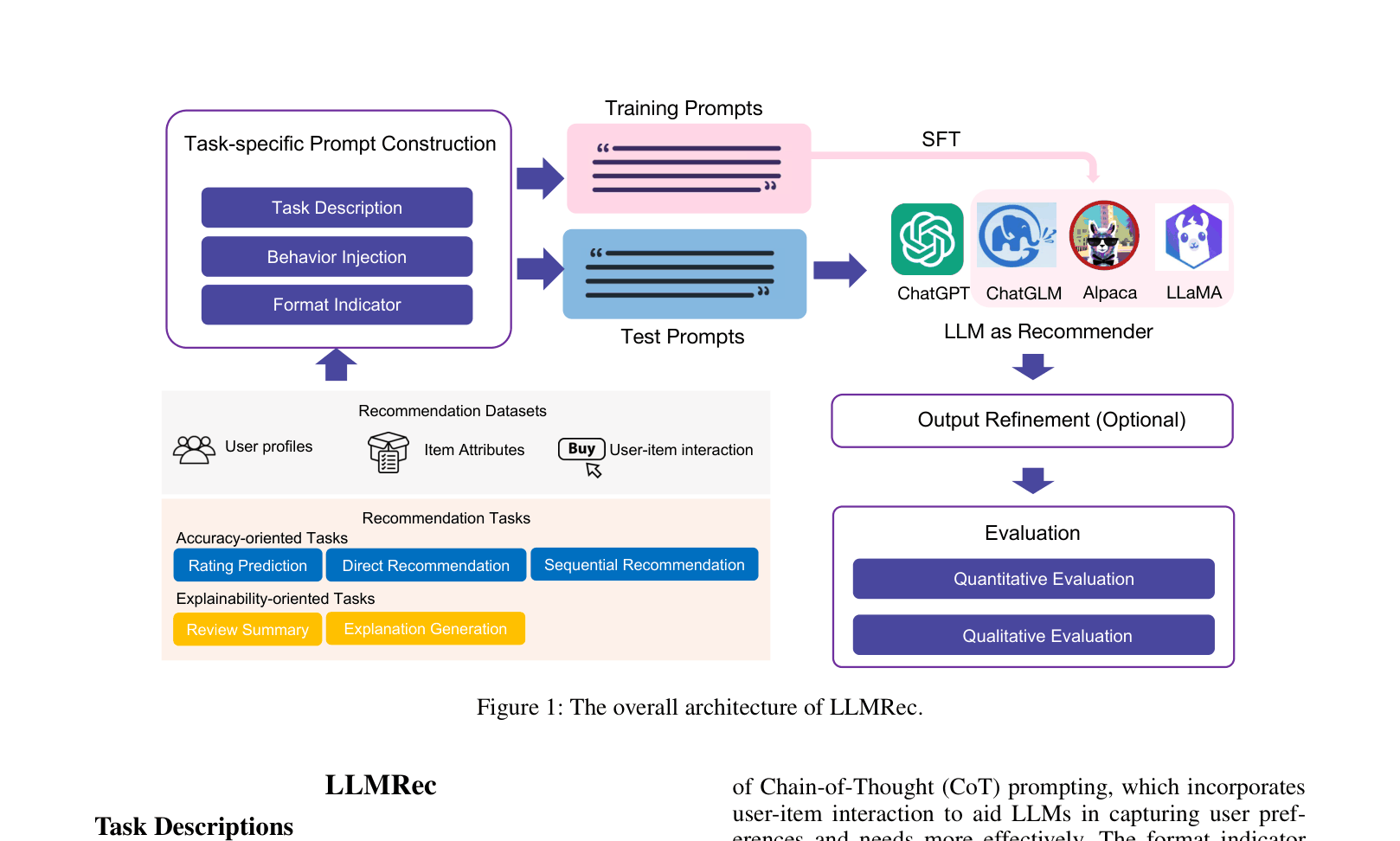
The overall architecture of LLMRec, illustrating the flow from data to recommendation output.
Evaluation Highlights
- Off-the-shelf ChatGPT significantly underperforms simple Matrix Factorization on Rating Prediction (RMSE 1.49 vs 1.19).
- Supervised Fine-Tuning (SFT) improves ChatGLM-6B's instruction compliance, enabling it to surpass ChatGPT in rating prediction (RMSE 1.29 vs 1.49).
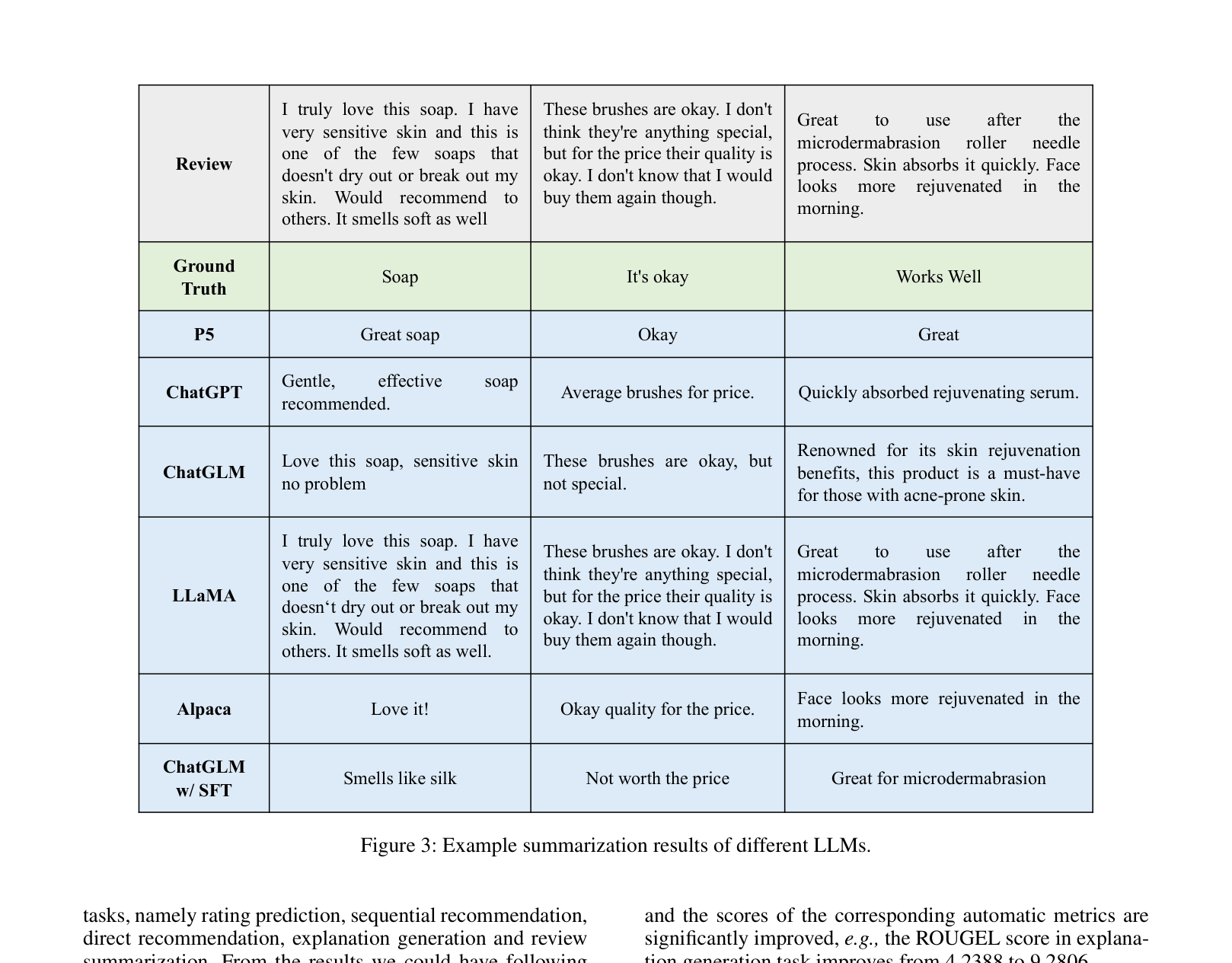
- In Review Summarization, off-the-shelf ChatGPT outperforms trained GPT-2 baselines (+2.8 ROUGE-L), showing strong zero-shot semantic understanding.
Breakthrough Assessment
7/10
A solid foundational benchmark that realistically exposes the limitations of LLMs in accuracy-based recommendation while highlighting their strengths in explainability. Established a clear baseline for future LLM4Rec work.