📝 Paper Summary
User Simulation
Generative Agents
Lusifer is a simulation environment that uses Large Language Models to generate dynamic, explainable user feedback and evolving profiles for training reinforcement learning recommender systems.
Core Problem
Traditional RL recommender training relies on static datasets that fail to capture evolving user preferences, while existing simulators lack realism or require complex, domain-specific hand-crafting.
Why it matters:
- Live user experiments are costly, risky, and ethically constrained, limiting the testing of new RL policies
- Static datasets (offline RL) suffer from distribution shifts and cannot simulate how a user reacts to a sequence of new recommendations
- Existing simulators like RecSim NG or Recogym either lack semantic realism or are too computationally complex to scale easily
Concrete Example:
A user might initially like 'Action' movies but shift towards 'Sci-Fi' after watching a specific series. A static dataset only records the final ratings. Lusifer simulates the *transition* after each batch of movies, explaining explicitly via text why the preference shifted.
Key Novelty
Incremental LLM-based User Profiling
- Processes user history in small sequential batches (e.g., 10 movies), prompting an LLM to update a textual summary of preferences after each batch
- Generates ratings for new items based strictly on this evolving textual profile and item metadata (overviews/tags), rather than collaborative filtering vectors
- Provides natural language explanations for *why* a user's profile changed or why a specific rating was given
Architecture
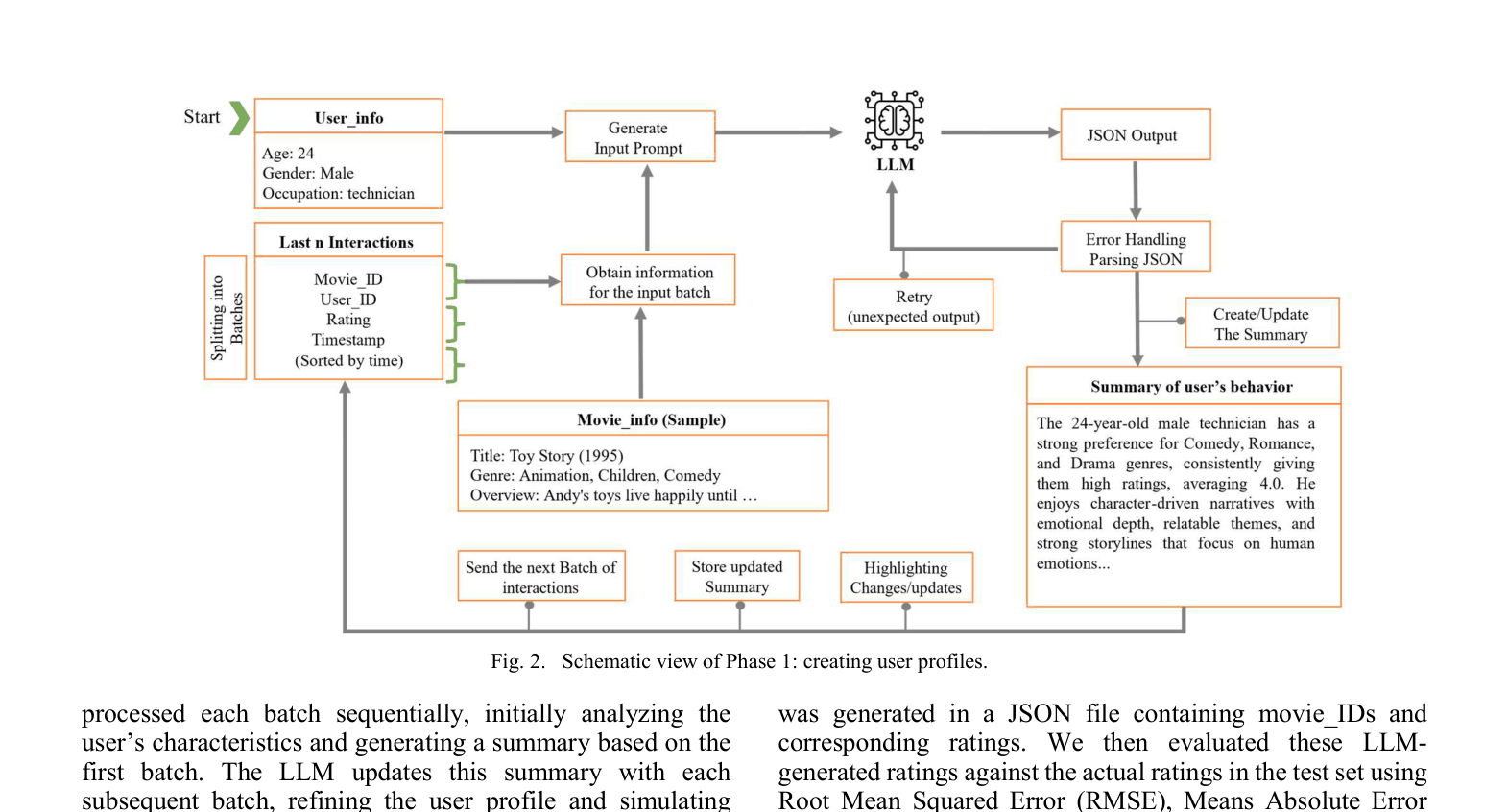
The two-phase pipeline: Profile Creation and Rating Generation
Evaluation Highlights
- Outperforms neural baselines in cold-start scenarios: Gemma:12B achieves 1.18 RMSE vs NCF's 1.29 on MovieLens 100K for users with <10 interactions
- Demonstrates capability to simulate feedback using only the last 40 interactions (approx. 30% of user history), reducing data reliance
- Provides interpretable justification for every profile update, unlike latent-factor baselines (SVD++, ALS) which are black boxes
Breakthrough Assessment
6/10
Novel application of LLMs for incremental user modeling in simulations. While it doesn't beat baselines on general accuracy, its explainability and cold-start performance make it a valuable tool for RL evaluation.