📝 Paper Summary
Recommender Systems
Large Language Model Integration
Llama4Rec improves recommendations by having LLMs and conventional models mutually augment each other's inputs and adaptively aggregating their outputs based on user interaction sparsity.
Core Problem
Conventional recommenders struggle with sparse data (long-tail), while LLMs struggle to capture collaborative filtering signals, and existing hybrid methods fail to fully leverage the complementary strengths of both.
Why it matters:
- Data sparsity and the long-tail problem significantly degrade recommendation quality for less active users in conventional systems
- Prior methods integrating LLMs often rely on complex ID embeddings that lack generalizability or only perform one-way augmentation (LLM enhancing data), missing the potential of conventional models to guide LLMs
Concrete Example:
In a movie recommendation scenario, a conventional model fails to recommend for a user with few interactions (cold start). An LLM can understand the user's text preferences but misses that similar users liked a specific niche movie. Llama4Rec uses the LLM to generate pseudo-interactions to train the conventional model, and uses the conventional model to find similar users to prompt the LLM, combining both signals.
Key Novelty
Mutual Augmentation and Adaptive Aggregation (Llama4Rec)
- Mutual Augmentation: LLMs generate synthetic interaction data to train conventional models (Data Augmentation), while conventional models provide collaborative context and prior predictions to the LLM via prompts (Prompt Augmentation)
- Adaptive Aggregation: A fusion mechanism that dynamically weighs the predictions of the LLM vs. the conventional model based on the user's interaction history (long-tail coefficient), trusting LLMs more for sparse users
Architecture
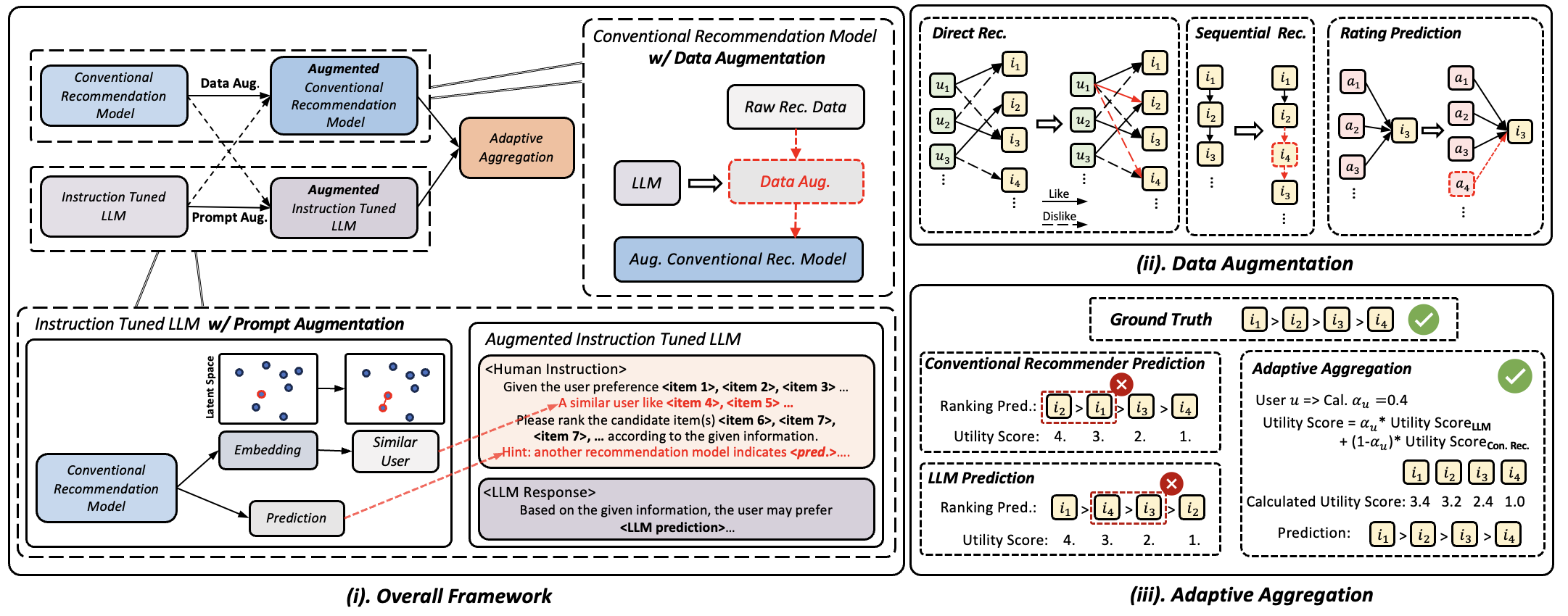
The Llama4Rec framework illustrating the three main components: data augmentation, prompt augmentation, and adaptive aggregation.
Evaluation Highlights
- Achieves up to +20.48% improvement in Hit@3 on the ML-100K dataset using LightGCN as the backbone compared to instruction-tuned baselines
- Demonstrates +14.21% average improvement in sequential recommendation tasks across tested datasets
- Outperforms state-of-the-art baselines (MixGCF, SGL) consistently across metrics (Hit@3, NDCG@3) on ML-1M and BookCrossing
Breakthrough Assessment
7/10
Offers a strong, model-agnostic framework for bidirectional enhancement between LLMs and collaborative filtering. While the components (augmentation, ensemble) are known, the specific mutual integration and adaptive weighting scheme are well-motivated and effective.