📝 Paper Summary
Reviewer Recommendation
Academic Graph Mining
OmniReview integrates multi-source academic data to create a verified peer-review benchmark and proposes a multi-task framework (Pro-MMoE) to balance reviewer recall, expertise discrimination, and ranking.
Core Problem
Existing reviewer recommendation datasets lack comprehensive scholar profiles, suffer from biased candidate labels (artificial annotation or restricted pools), and use simplistic metrics that fail to filter unqualified candidates.
Why it matters:
- Editorial workflows struggle to match growing submissions with qualified experts due to fragmented data
- Current metrics (standard retrieval) suffer from false negative bias, penalizing valid but unassigned experts
- Existing systems fail to distinguish between true experts and 'hard negatives' who share keywords but lack deep domain expertise
Concrete Example:
A researcher with strong credentials in a broad field (e.g., 'Machine Learning') might be recommended for a specific sub-field paper (e.g., 'Molecular Dynamics') due to keyword overlap, despite having zero publications in that specific niche.
Key Novelty
OmniReview Benchmark & Pro-MMoE Framework
- Constructs a massive dataset (202k+ reviews) by aligning OAG, Frontiers, and ORCID data via a multi-step entity disambiguation pipeline
- Defines a three-tier evaluation hierarchy: Recall (finding experts), Discrimination (rejecting superficial matches), and Ranking (ordering valid candidates)
- Proposes Pro-MMoE: Synergizes LLM-generated semantic profiles for interpretability with a Task-Adaptive Mixture-of-Experts architecture to balance conflicting evaluation goals
Architecture
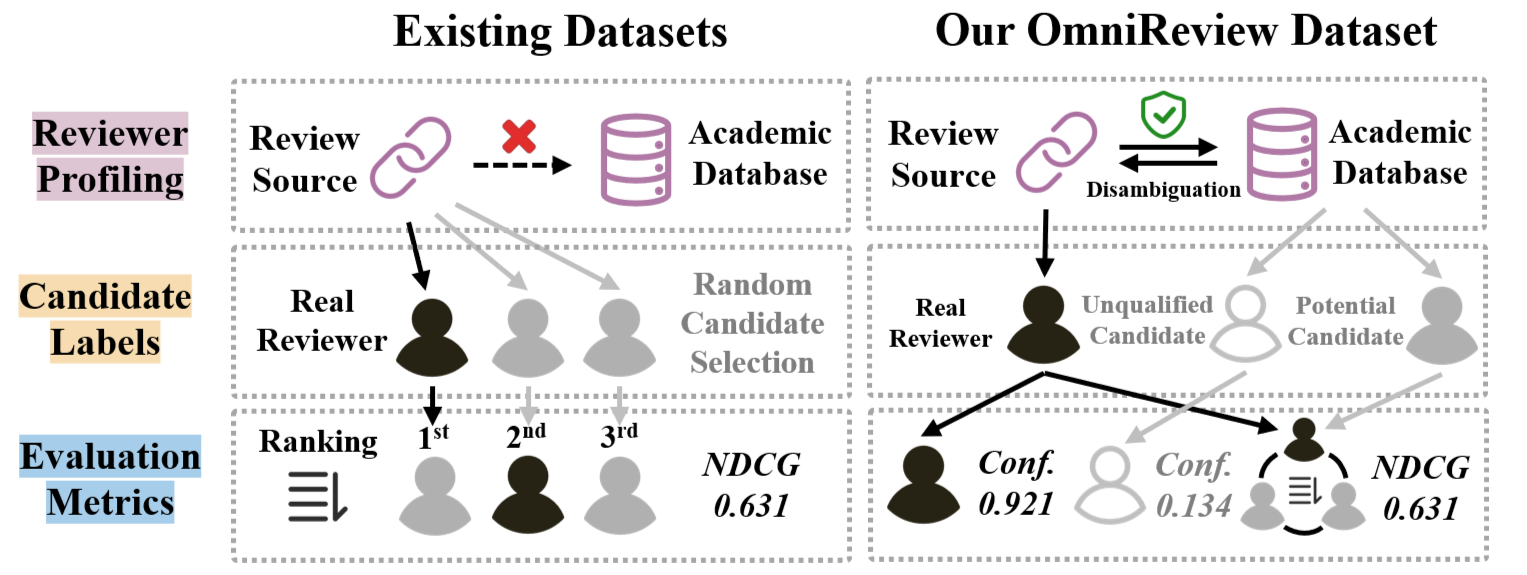
Illustrates the limitations of existing datasets (Insufficient Profiling, Biased Labels, Simplistic Metrics) versus the OmniReview approach.
Evaluation Highlights
- Dataset comprises 202,756 verified review records and 150,287 identified reviewers
- Pro-MMoE improves Task 3 (Ranking) by +17.15% over state-of-the-art baselines [Note: Absolute values not in text]
- Pro-MMoE improves Task 2 (Discrimination) by +5.39% over state-of-the-art baselines [Note: Absolute values not in text]
Breakthrough Assessment
8/10
Significant contribution to infrastructure (large-scale verified dataset) and methodology (addressing the hard-negative/discrimination problem often ignored in retrieval tasks).