📝 Paper Summary
Content-based Recommendation
Recommender Systems Libraries
Legommenders is a modular library enabling the joint training of content encoders (including LLMs) and behavior modules to create inductive recommender systems that handle cold-start problems better than traditional ID-based methods.
Core Problem
Traditional recommender libraries rely on ID-based transductive learning (failing on cold-start) or decoupled content encoding where features are pre-extracted and frozen, leading to suboptimal alignment with specific recommendation tasks.
Why it matters:
- Pre-trained embeddings from decoupled encoders are often too general and not aligned with specific recommendation contexts, reducing accuracy
- ID-based methods struggle with new users or items (cold start) and cannot adapt to shifts in user preference over time
- Existing libraries do not natively support the end-to-end fine-tuning of Large Language Models (LLMs) within the recommendation pipeline
Concrete Example:
In news recommendation, a standard library might use a frozen BERT model to extract vectors from news titles once, then train a separate ID-based model. Legommenders allows fine-tuning the BERT layers *jointly* with the user's click history, ensuring the text embeddings are optimized specifically for predicting that user's interests.
Key Novelty
Modular Joint Training for Content-Based Recommendation
- Decomposes recommendation into three jointly trainable modules: Content Operator (item encoding), Behavior Operator (user sequence fusion), and Click Predictor
- integrates LLMs directly as Content Operators with support for parameter-efficient fine-tuning (PEFT/LoRA), unlike previous libraries that only accepted static features
- Implements an inference caching pipeline that pre-computes embeddings, separating heavy content encoding from lightweight interaction prediction
Architecture
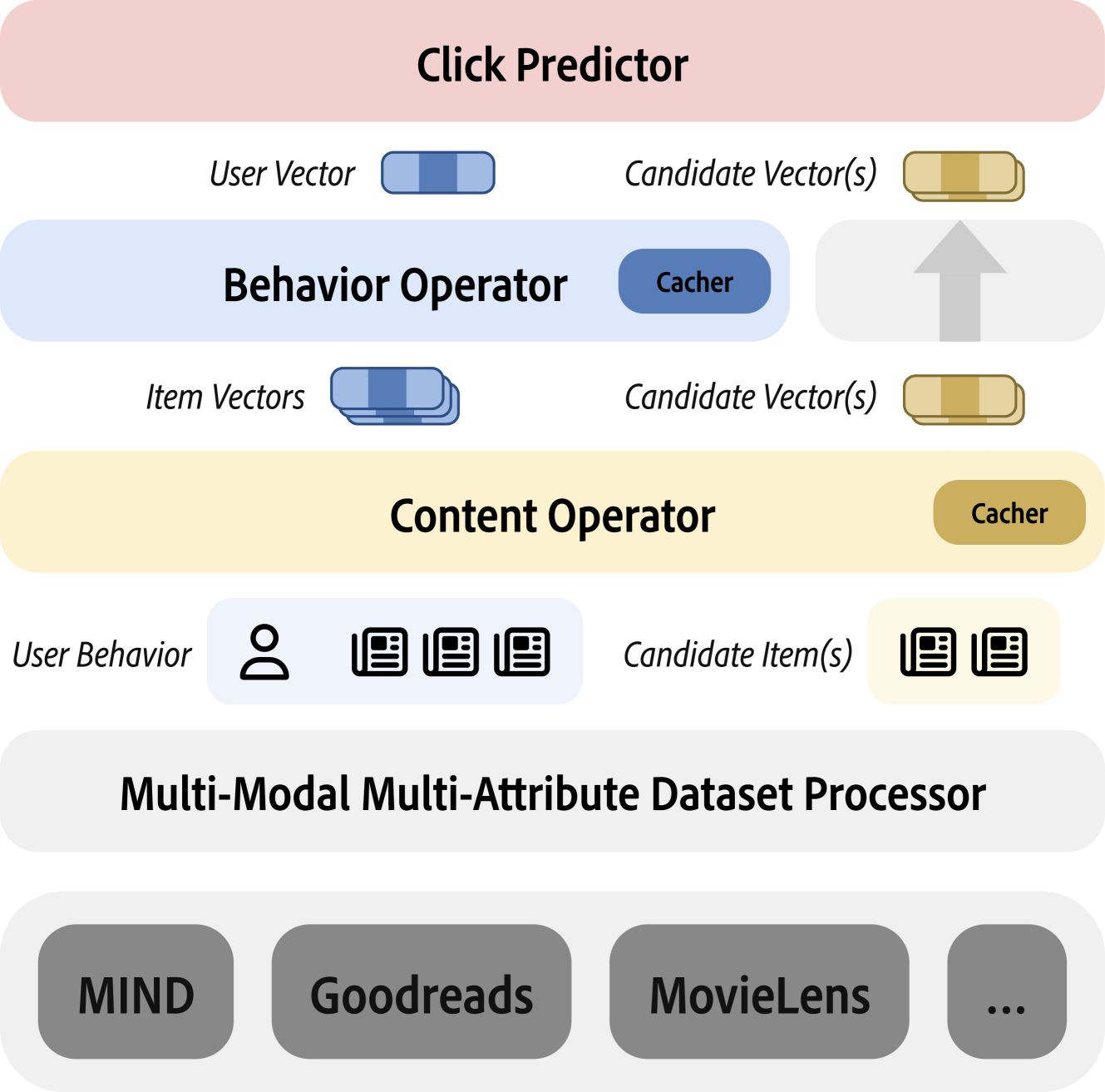
The core architecture of Legommenders, illustrating the four components and the caching mechanism.
Evaluation Highlights
- Offers over 1,000 distinct model combinations (95% previously untested) across 15 datasets
- Achieves up to 50x speedup in evaluation via a novel caching pipeline that avoids redundant content encoding
- Achieves up to 100x training acceleration using a split-mode training method (freezing lower LLM layers) compared to full fine-tuning
Breakthrough Assessment
8/10
Significantly modernizes recommender system development by unifying content-based deep learning with LLMs in a modular, efficient, and trainable framework, addressing the major limitation of decoupled architectures.