📝 Paper Summary
LLM for Recommendation
Collaborative Filtering integration in LLMs
Parameter-efficient fine-tuning (PEFT)
CoRA injects collaborative filtering signals into Large Language Models by transforming user-item embeddings into temporary model weights (like LoRA) rather than modifying the text prompt.
Core Problem
Existing methods integrate collaborative information by adding tokens to the text prompt and fine-tuning, which degrades the LLM's general reasoning abilities and disrupts text semantics.
Why it matters:
- Fine-tuning on recommendation data causes 'catastrophic forgetting,' weakening the LLM's ability to reason, summarize, and understand general text
- Inserting collaborative embeddings as tokens into prompts breaks the natural language structure, confusing the LLM and leading to hallucinations or sub-optimal predictions
- Current approaches force a trade-off between leveraging collaborative signals (crucial for recommendation accuracy) and maintaining the LLM's powerful text inference capabilities
Concrete Example:
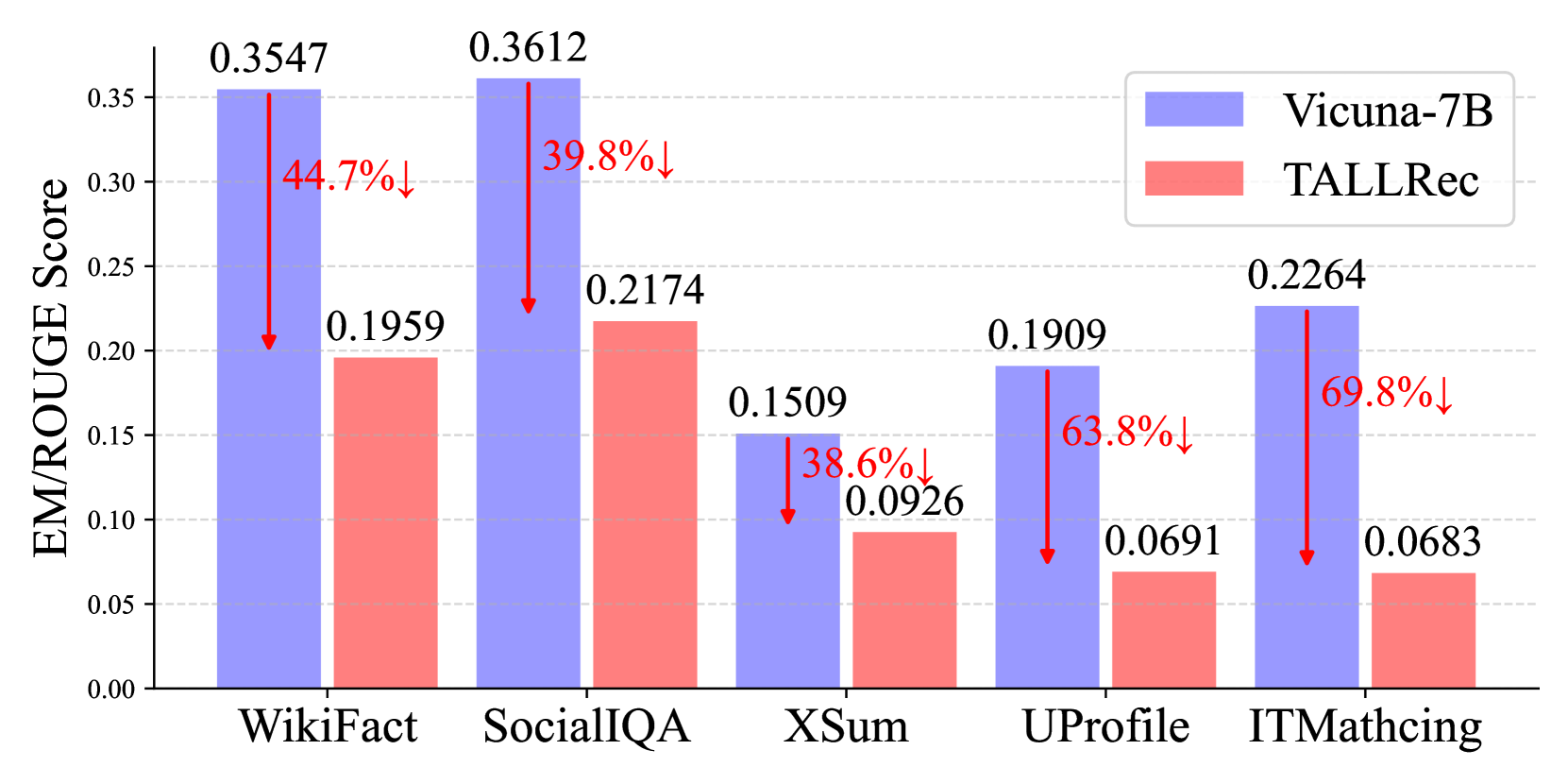
When Vicuna-7B is fine-tuned with standard recommendation prompts (like TALLRec), its performance on general knowledge tasks (WikiFact) drops significantly. Additionally, inserting user/item tokens into a prompt asking to 'repeat the description' causes the model to output gibberish instead of the original text.
Key Novelty
Collaborative LoRA (CoRA)
- Instead of treating collaborative data as input text, CoRA treats it as a modifier to the model's processing logic (weights)
- A generator converts user/item embeddings into 'collaborative weights' that temporarily merge with the LLM's attention weights, similar to how LoRA adds update matrices
- This allows the LLM to 'perceive' user preferences without changing its input text or permanently altering its pre-trained general knowledge
Architecture
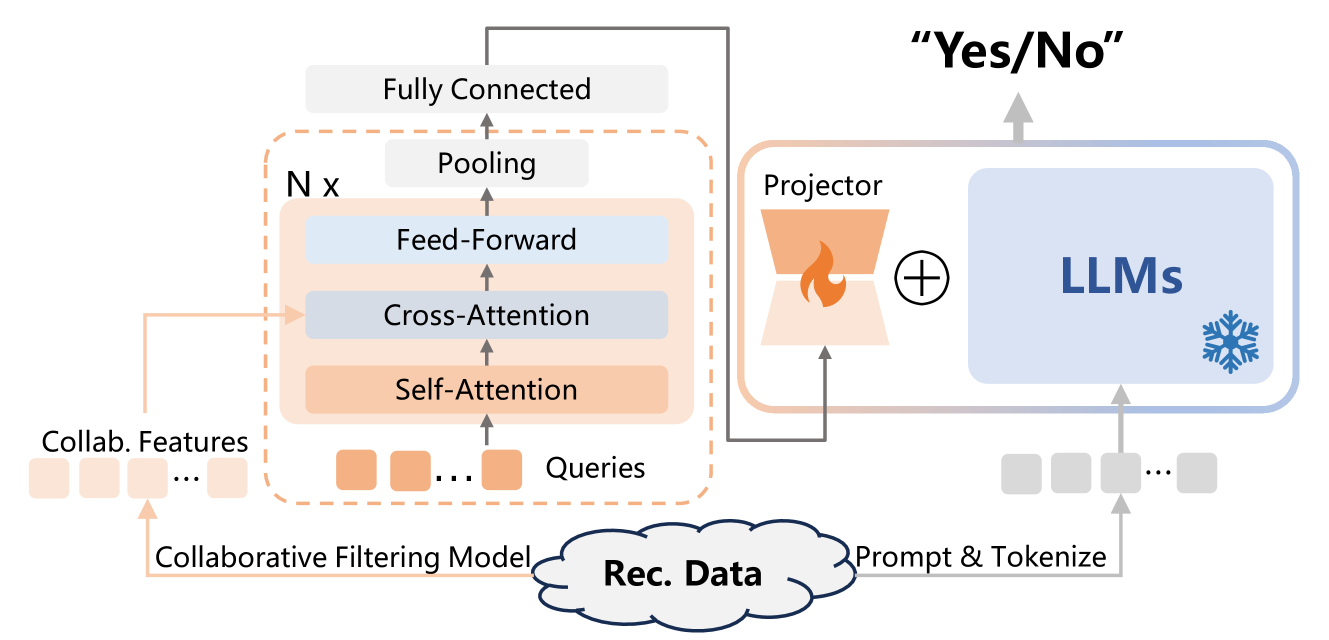
The overall framework of CoRA. It illustrates the flow from User/Item Embeddings -> Collaborative Query Generator -> Low-Rank Weight Generation -> Injection into LLM Backbone.
Evaluation Highlights
- Outperforms state-of-the-art LLM-based method (BinLLM) by significant margins on Amazon-Book and Yelp datasets
- Achieves higher recommendation accuracy than traditional Collaborative Filtering models (like SASRec and LightGCN) while retaining text reasoning capabilities
- Preserves general LLM capabilities (evaluated on WikiFact, SocialIQA) where fine-tuning methods like TALLRec show significant degradation
Breakthrough Assessment
7/10
Novel approach applying vision-inspired weight-space injection (VLoRA) to recommendation. effectively solving the prompt-disruption problem. Strong results, though reliance on pre-trained CF embeddings limits it to a hybrid role.