📝 Paper Summary
LLM-based Recommendation
Reasoning in Recommender Systems
R2ec integrates reasoning and recommendation into a single LLM with a dual-head architecture, using a reinforcement learning framework to jointly optimize reasoning chains and efficient item prediction without human annotations.
Core Problem
Current approaches decouple reasoning from recommendation (requiring two separate models) or rely on slow autoregressive decoding of item IDs, leading to high latency and suboptimal disjoint optimization.
Why it matters:
- Running separate reasoning and recommendation models doubles resource costs and latency
- Alternate optimization (freezing one module to train the other) prevents true end-to-end alignment of reasoning rationales with ranking objectives
- Autoregressive generation of item identifiers in large models is computationally expensive compared to direct prediction
Concrete Example:
A standard reasoning recommender might first use a large LLM to generate a user profile analysis, then pass that text to a separate BERT-based ranker to score items. This requires maintaining two heavy models in memory and prevents the ranker's errors from directly updating the LLM's reasoning logic during training.
Key Novelty
Unified Dual-Head Large Recommender (R2ec)
- Equips a decoder-only LLM with two heads: a language head for generating reasoning chains and a recommendation head for single-step item prediction
- Uses the RecPO framework to train without reasoning annotations by sampling diverse reasoning paths and optimizing them via a fused reward (ranking + similarity)
Architecture
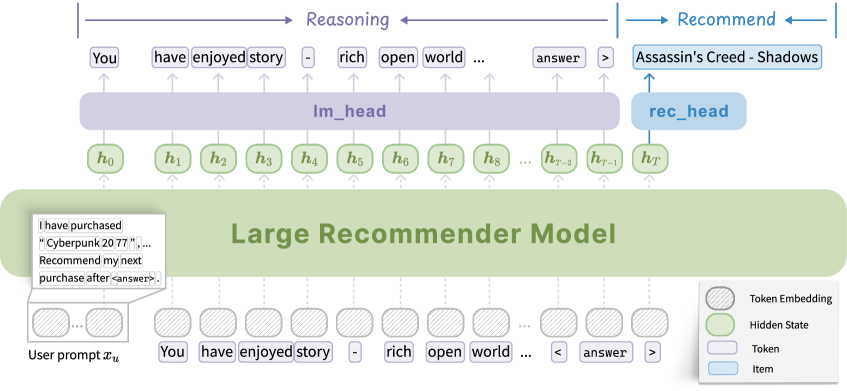
The dual-head architecture of R2ec and the inference flow.
Breakthrough Assessment
8/10
Proposes a unified architecture that solves the latency bottleneck of reasoning recommenders while enabling end-to-end RL training. Strong theoretical contribution in the RecPO framework.