📝 Paper Summary
Conversational Recommender Systems (CRS)
Generative Retrieval
Multimodal LLMs
TalkPlay reformulates music recommendation as a language generation task by extending an LLM's vocabulary with discrete tokens representing audio, lyrics, and cultural context, enabling direct recommendation within conversation.
Core Problem
LLMs cannot natively 'speak' music because items are typically stored as abstract IDs in external databases, creating a semantic gap between the conversation and the music catalog.
Why it matters:
- Traditional recommenders rely heavily on listening history, failing when users want to express specific intent via natural language (zero-shot scenarios)
- Existing text-to-music retrieval is often single-turn, preventing users from refining their requests through dialogue
- Two-stage systems (dialogue manager + separate recommender) lose the rich semantic context of the conversation during the retrieval step
Concrete Example:
A user asks for 'sad songs with upbeat rhythms like [Artist]'. A traditional system might just search metadata for 'sad' and the artist. TalkPlay generates specific audio tokens for 'upbeat rhythm' and semantic tokens for 'sad' directly in the response, mapping them to songs that actually sound that way.
Key Novelty
Multimodal Generative Recommendation via Vocabulary Expansion
- Treats a song not as a database ID, but as a sequence of 'words' (tokens) describing its playlist context, mood, metadata, lyrics, and audio
- Expands the LLM's dictionary to include these music words, allowing it to 'write' a song recommendation just like it writes a sentence
- Unifies the recommender and chatbot into a single model that predicts music features based on conversation history
Architecture
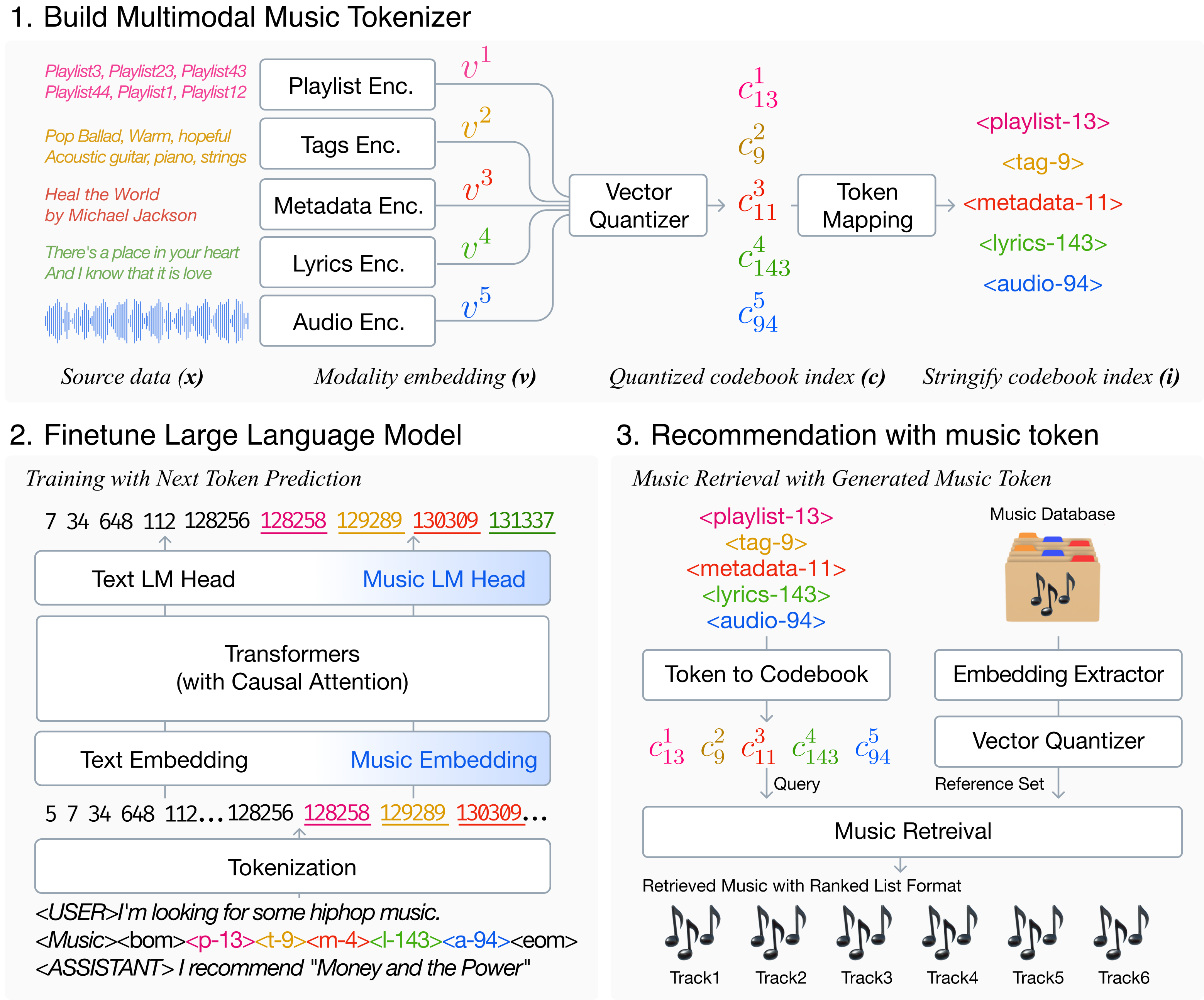
Overview of TalkPlay system showing Music Tokenizer and LLM integration.
Evaluation Highlights
- Proposed tokenization scheme represents theoretically 1,126 trillion unique music items using combinations of 5 modality tokens
- Model size increased by only <1% (10.5M parameters) while adding full multimodal recommendation capabilities
- Identified 'Playlist Co-occurrence' as the most critical feature for recommendation, assigned highest weight (25) compared to audio (1) in the matching algorithm
Breakthrough Assessment
7/10
Clever unification of generative retrieval and multimodal understanding for music. While the approach is sound and the tokenization robust, the reliance on exact/partial token matching for retrieval might limit scalability compared to dense vector search.