📝 Paper Summary
User Simulation for Recommender Systems
LLM-based Agents
AlignUSER trains LLM agents to act as faithful user simulators by teaching them environment dynamics via next-state prediction and aligning their decisions with human preferences through counterfactual self-reflection.
Core Problem
Existing LLM-based user simulators rely on few-shot prompting, resulting in a shallow understanding of environment dynamics and behavior that reflects the model's priors rather than genuine user patterns.
Why it matters:
- Offline metrics (e.g., nDCG) often misalign with real online user behavior and business value
- Online A/B testing is expensive, slow, and risky
- Without internalizing how actions affect future states, agents struggle with long-term consequences (e.g., when to exit vs. purchase)
Concrete Example:
When simulating an e-commerce user, a standard LLM agent might prematurely 'exit' or erratically rate similar items differently because it doesn't understand that clicking an item leads to a detailed page or how its persona dictates consistent preferences.
Key Novelty
World-Model-Driven Agent Alignment
- Pre-trains the agent's policy on a world-modeling task where it must predict the text description of the next state (e.g., the next web page) given an action, internalizing environment dynamics
- Aligns actions via a counterfactual reflection mechanism: the agent generates alternative actions, simulates their outcomes, and produces a chain-of-thought explaining why the human demonstration was superior
Architecture
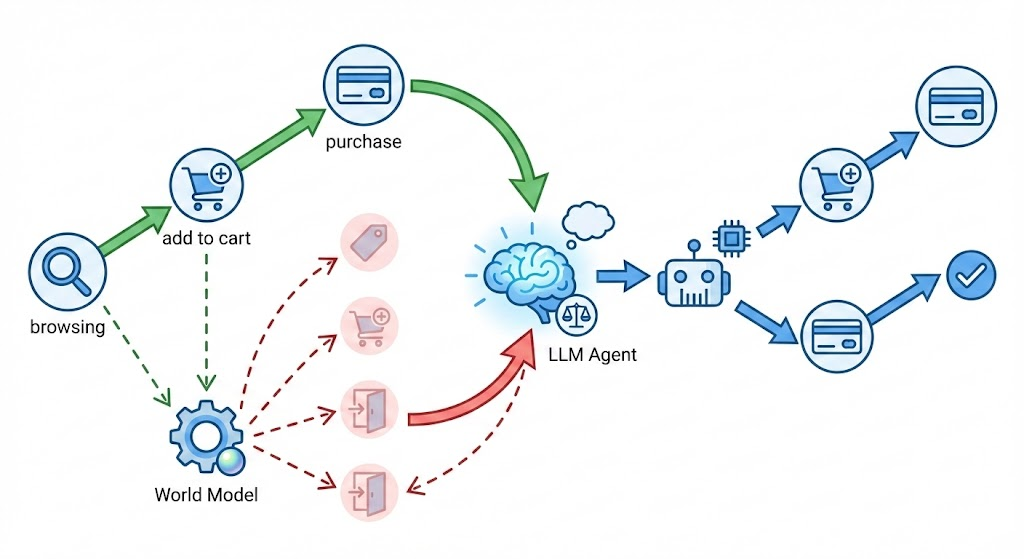
The overall architecture of AlignUSER, illustrating the two-stage training process (World Model Pretraining + Counterfactual Alignment) and the inference loop.
Evaluation Highlights
- +13.1% accuracy improvement over Agent4Rec in predicting session outcomes (purchase/exit) on the AmazonBook dataset (AlignUSER+)
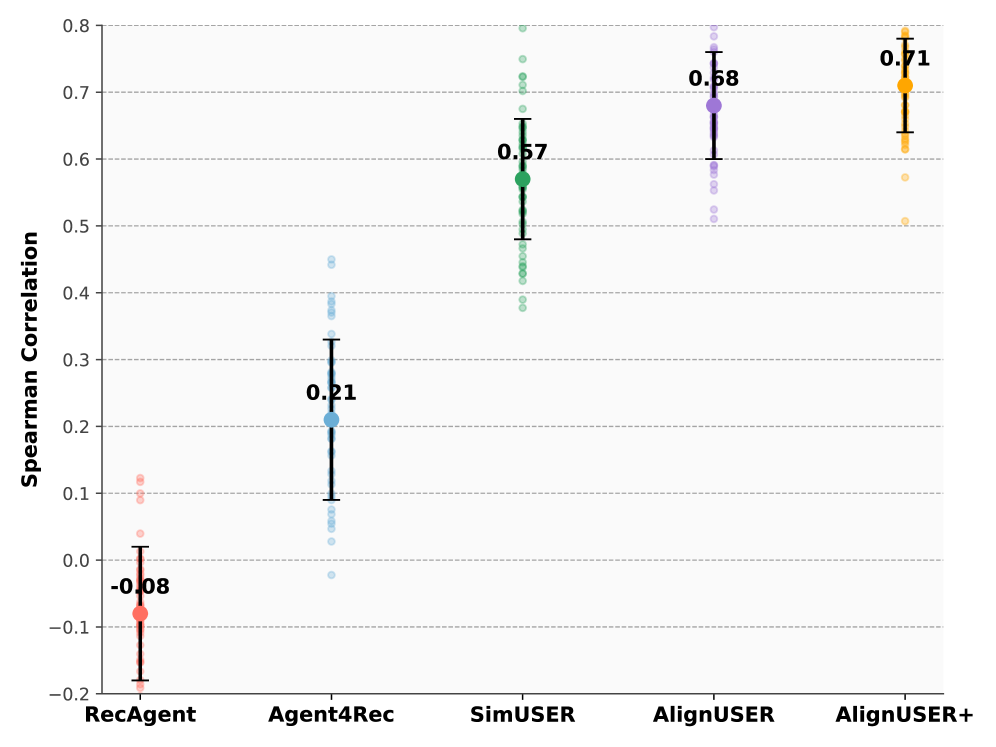
- Higher correlation with real-world online A/B tests (Spearman correlation ~0.7-0.8 range) compared to SimUSER and traditional offline metrics
- Achieves significantly higher human-likeness scores (4.45/5 vs. 2.95/5 for Agent4Rec) as judged by GPT-4o on the AmazonBook dataset
Breakthrough Assessment
8/10
Strong methodological contribution by combining world models with counterfactual reasoning for user simulation. Demonstrates superior correlation with real A/B tests, addressing a major pain point in RS evaluation.