📝 Paper Summary
Model Compression
Efficient Inference
Recommendation Systems
This paper presents a three-stage pipeline (distillation, structured pruning, and re-distillation) to compress 100B+ parameter recommendation models into efficient small language models while maintaining ranking accuracy.
Core Problem
Massive language models (100B+ parameters) offer superior performance for recommendation tasks but incur prohibitively high latency and infrastructure costs for real-time serving.
Why it matters:
- Real-time recommendation systems require extremely low latency (milliseconds) to rank hundreds of items per user request
- Deploying 100B+ models at scale is economically impractical due to hardware requirements
- Standard compression techniques often degrade model utility (accuracy/AUC) significantly on sensitive ranking tasks
Concrete Example:
A social network needs to rank a feed of items for a user. Using a 100B+ MoE model for every item incurs massive prefill latency. A compressed 3B model is needed that mimics the 100B model's ranking decisions without the computational cost.
Key Novelty
Distill-Prune-Redistill Pipeline for RecSys
- Combines Knowledge Distillation (transferring knowledge from a 100B+ teacher) with One-Shot Structured Pruning (removing MLP neurons and attention heads) in a specific sequence
- Crucially employs a 're-distillation' phase after pruning to recover lost generalization capabilities, using the unpruned student as the new teacher
- Validates the pipeline on industrial-scale recommendation workloads (ranking and reasoning) rather than just generic NLP benchmarks
Architecture
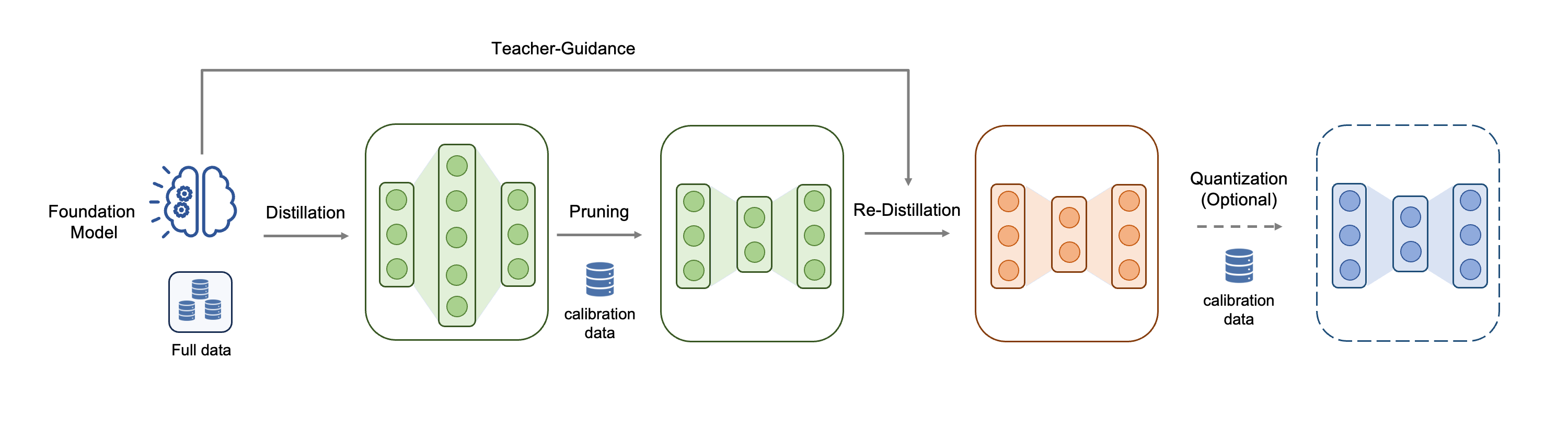
The three-stage model compression pipeline: (1) Distillation of FM to Student, (2) One-shot Structured Pruning, (3) Re-distillation/Fine-tuning of the Pruned Model.
Evaluation Highlights
- Distilled Llama-3.1-8B model retains ranking performance within -0.06% AUC of the 100B+ foundation model, vastly outperforming standard fine-tuning (-0.62% drop)
- Structured pruning of attention heads yields a >28% speedup in prefill latency
- In a live A/B test for a reasoning task, the distilled model improved an internal quality metric (IQM) by 20.29% compared to the previous baseline
Breakthrough Assessment
7/10
Strong practical contribution demonstrating a complete recipe for deploying LLMs in large-scale RecSys. While the individual techniques (KD, Pruning) are known, the specific integration and industrial validation on 100B+ models are significant.