📝 Paper Summary
Synthetic Data Generation
Reasoning in Large Language Models
Vision-Language Models (VLMs)
MindGYM is a framework that enables models to synthesize their own high-quality training data by explicitly injecting structured cognitive patterns into the generation process.
Core Problem
Existing instruction datasets are labor-intensive to scale, while current synthetic methods often produce shallow or logically inconsistent data because they lack structured cognitive guidance.
Why it matters:
- Manual curation of datasets like OK-VQA is expensive and hard to scale up
- Self-supervised methods (e.g., MMInstruct) suffer from limited generalization and fail to produce cognitively diverse data
- Reinforcement learning methods for reasoning (e.g., RL4F) incur prohibitive computational costs
Concrete Example:
When asked a complex question requiring multi-step deduction, a standard model might provide a superficial answer. Standard synthetic methods often generate simple single-hop QAs that fail to teach the model how to break down the problem, whereas MindGYM forces the synthesis of an explicit 'thinking trace' alongside the answer.
Key Novelty
MindGYM (Thinking-Centric Data Synthesis)
- Injects specific 'thinking priors' (breadth, depth, progression) into the prompt design to guide data generation toward cognitively rich samples
- Uses a multi-stage synthesis process: generating background context → seed single-hop questions → challenging multi-hop questions via composition operators
- Employs a structured learning pathway: training evolves from guided answering (with thinking traces) to autonomous solving (internalized reasoning)
Architecture
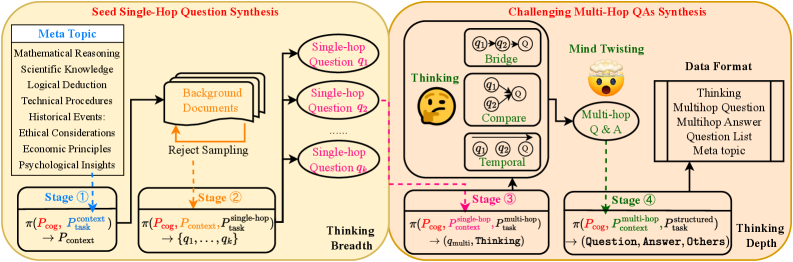
The MindGYM framework pipeline showing the transition from cognitive topics to final multi-hop QA data.
Evaluation Highlights
- +16% improvement on MathVision-Mini for Qwen2.5-VL-7B using only 400 synthetic samples
- Synthetic data achieves 16.7% higher average quality and 67.91% lower quality variance compared to baseline sources on Qwen2.5-VL-32B
- Outperforms Chain-of-Thought (CoT) and Tree-of-Thoughts (ToT) baselines on six reasoning benchmarks
Breakthrough Assessment
8/10
Strong empirical results with very little data (400 samples) and a principled approach to reducing data quality variance, addressing a key bottleneck in synthetic data scaling.