📝 Paper Summary
Recommendation Simulation
Generative Agents
Agent4Rec simulates 1,000 LLM-driven users with profile, memory, and action modules to evaluate recommender systems and uncover causal relationships in user behavior.
Core Problem
Traditional recommender system research suffers from a disconnect between offline metrics (accuracy on historical data) and online performance, hindering realistic evaluation and feedback loops.
Why it matters:
- Offline metrics often fail to capture real-time user satisfaction, leading to poor deployment outcomes.
- Testing algorithms on real users is risky and expensive; a faithful simulator could revolutionize testing and data collection.
- Existing simulators lack the cognitive depth and personalized reasoning capabilities offered by modern Large Language Models (LLMs).
Concrete Example:
In standard offline evaluation, a model is judged on predicting held-out ratings. However, this ignores dynamic factors like user fatigue or the 'filter bubble' effect, where a user gets bored of repeated similar recommendations—phenomena Agent4Rec can simulate.
Key Novelty
LLM-Empowered Generative User Simulator (Agent4Rec)
- Agents are initialized with social traits (activity, conformity, diversity) derived from real datasets (MovieLens, etc.) rather than random assignment.
- Introduces an emotion-driven memory module where agents reflect on 'fatigue' and 'satisfaction' to decide whether to continue browsing or exit, mimicking human disengagement.
- Utilizes a page-by-page interaction mode where agents view lists, rate items, and provide interview-style feedback, creating a dynamic feedback loop for the recommender.
Architecture
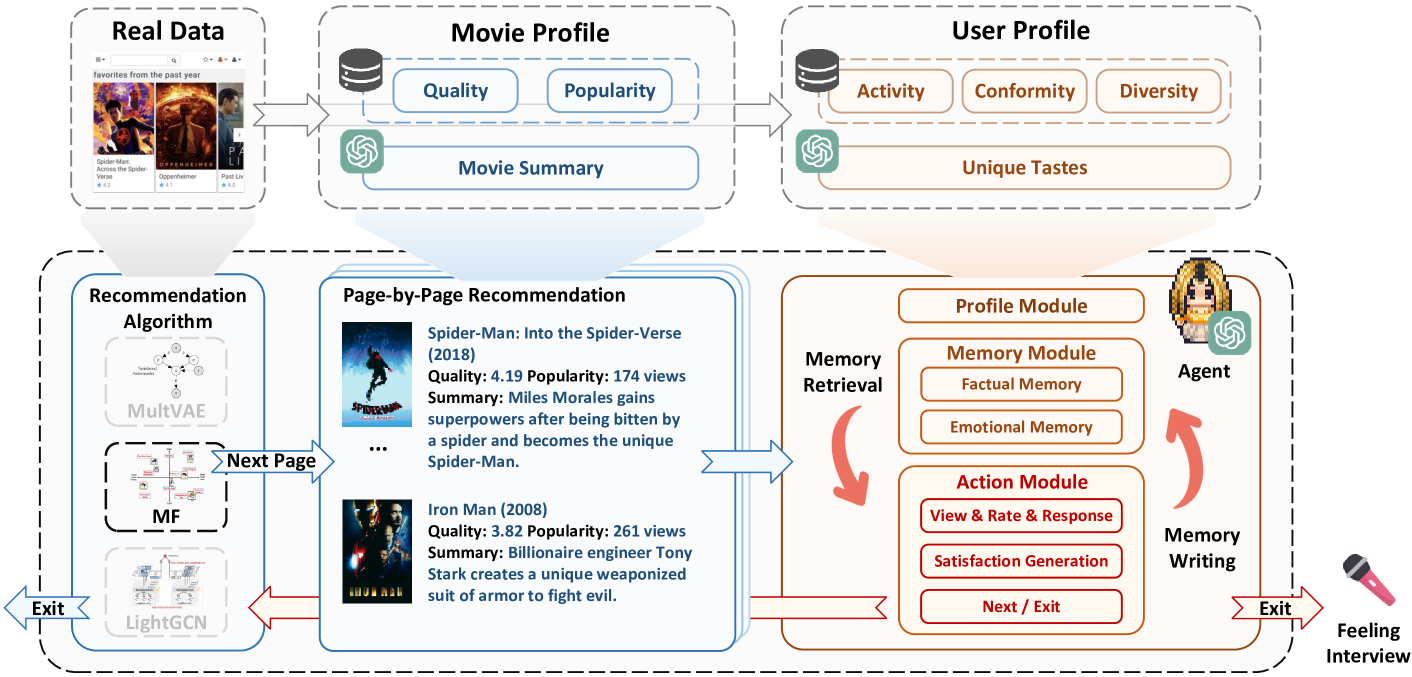
The overall architecture of Agent4Rec, illustrating the interaction between the User (Agent) and the Recommender System.
Evaluation Highlights
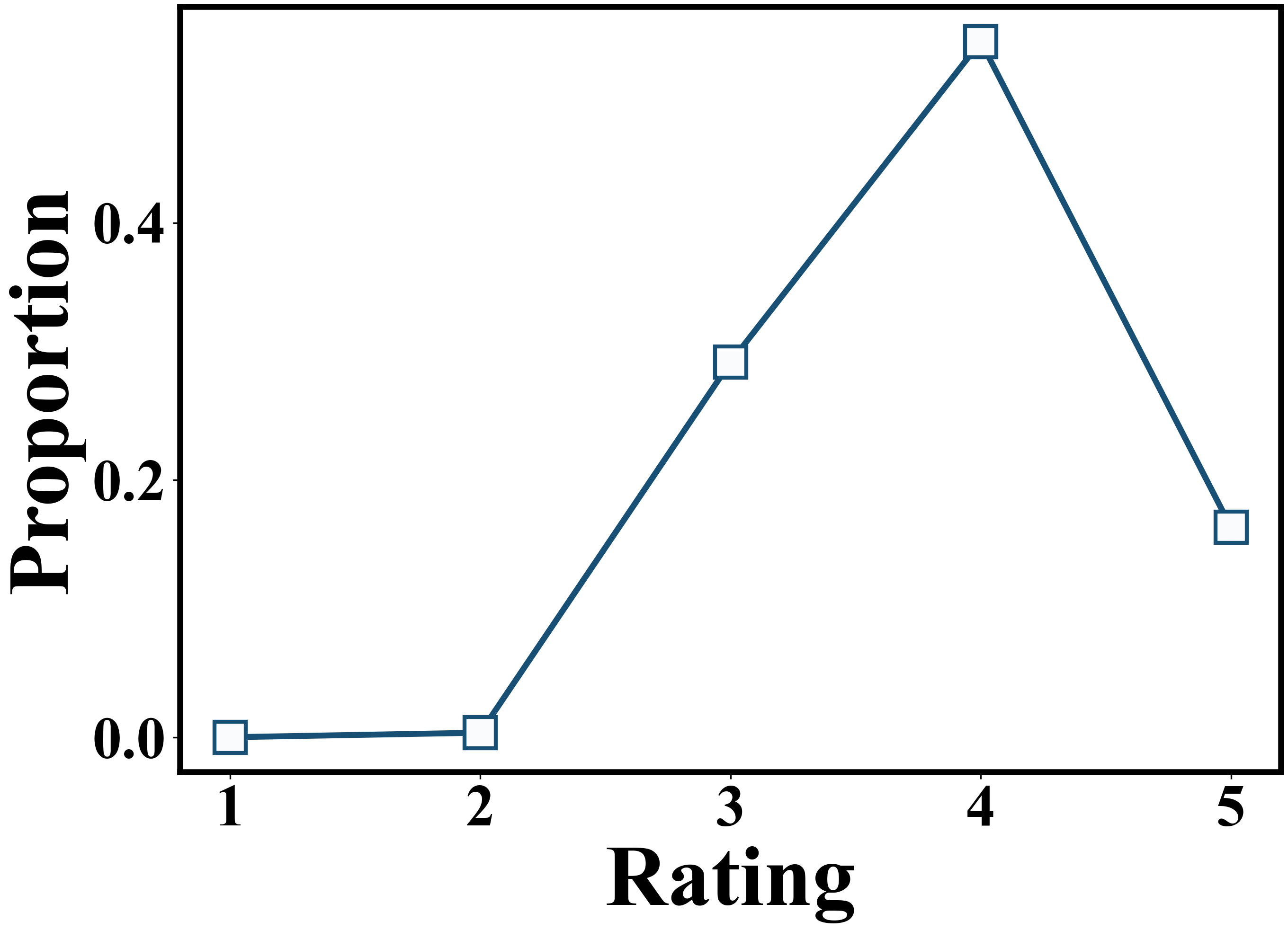
- Agents faithfully replicate user rating distributions, achieving high correlation with ground truth on MovieLens (Spearman correlation > 0.6 for rating count distributions).
- Identifies the 'filter bubble' effect: as recommendation rounds increase, the diversity of exposed item genres drops by ~15-20% for accuracy-focused models like Matrix Factorization.
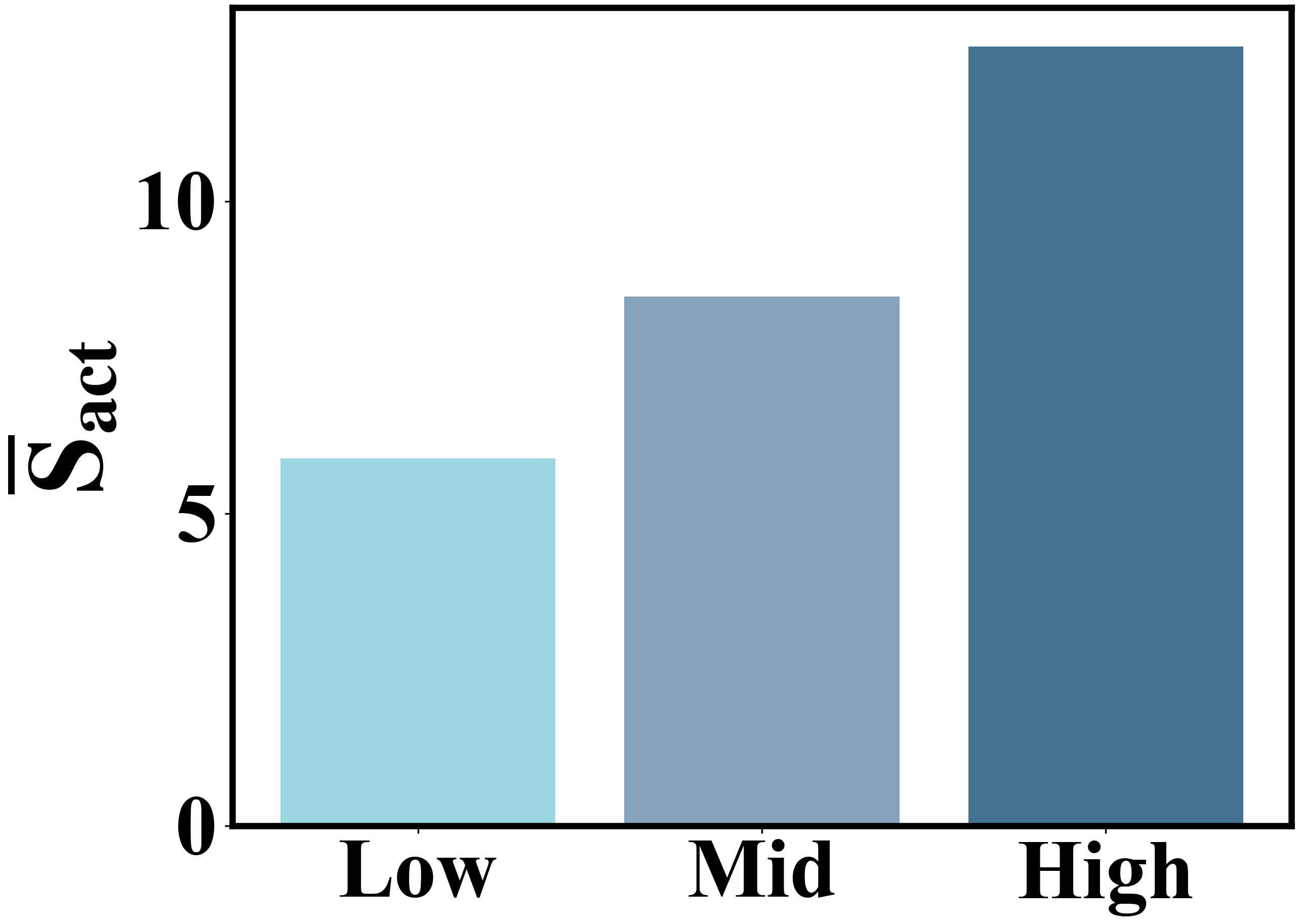
- Causal discovery experiments using agent data successfully recover the causal graph of user interactions (e.g., identifying that 'Conformity' causes 'Rating'), validating the simulator's logical consistency.
Breakthrough Assessment
7/10
A strong step toward realistic user simulation using LLMs. While it doesn't propose a new recommendation algorithm, it offers a novel evaluation platform that captures psychological factors (fatigue, emotion) absent in traditional metrics.