📝 Paper Summary
LLM-based Recommendation
Reinforcement Learning for LLMs
RecZero trains a single LLM to autonomously reason about user-item compatibility using reinforcement learning optimized for rating accuracy, bypassing the need for flawed teacher-model distillation.
Core Problem
Existing reasoning-enhanced recommenders rely on distilling knowledge from general-purpose teacher LLMs (like ChatGPT), which often lack domain-specific recommendation capabilities and produce reasoning traces misaligned with the final rating prediction.
Why it matters:
- General-purpose teachers produce 'hallucinated' or irrelevant reasoning that hurts the student model's accuracy when distilled
- Distillation is passive; the student model mimics surface-level patterns without learning how to actively reason to improve prediction accuracy
- Generating high-quality supervision data from API-based teacher models is expensive and static
Concrete Example:
A general teacher model might generate a reasoning trace focusing on a user's love for 'action movies' to justify a high rating for a specific DVD, but fail to notice the user specifically dislikes the 'director' of that film. A student model distilled on this mimics the superficial 'action movie' logic and fails to predict the correct low rating.
Key Novelty
RecZero (Pure RL) and RecOne (Hybrid SFT+RL)
- **RecZero**: Abandons the teacher-student pipeline. Trains a single LLM using Group Relative Policy Optimization (GRPO) to generate reasoning steps (`<analyze user>`, `<match>`) that are directly rewarded based on how close the final rating is to the ground truth.
- **RecOne**: Enhances RecZero by initializing the model with 'rationalized' data. A teacher generates reasoning; if the rating is wrong, the teacher is forced to regenerate reasoning that matches the true rating, creating a high-quality cold-start dataset.
Architecture
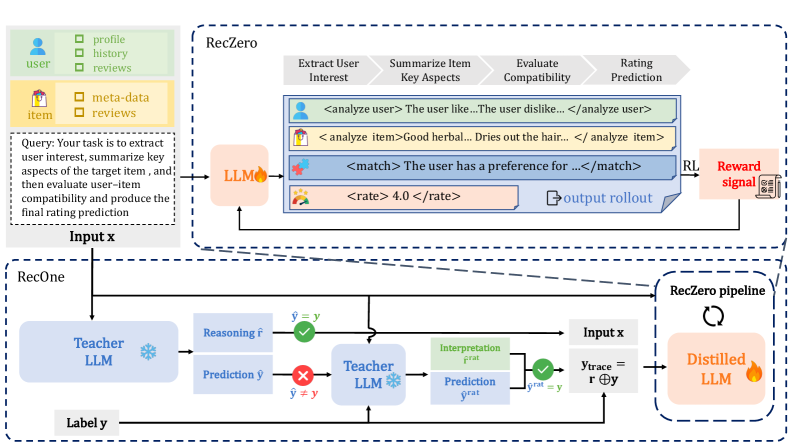
Comparison of the traditional Distillation Paradigm vs. the proposed RecZero/RecOne Paradigm.
Evaluation Highlights
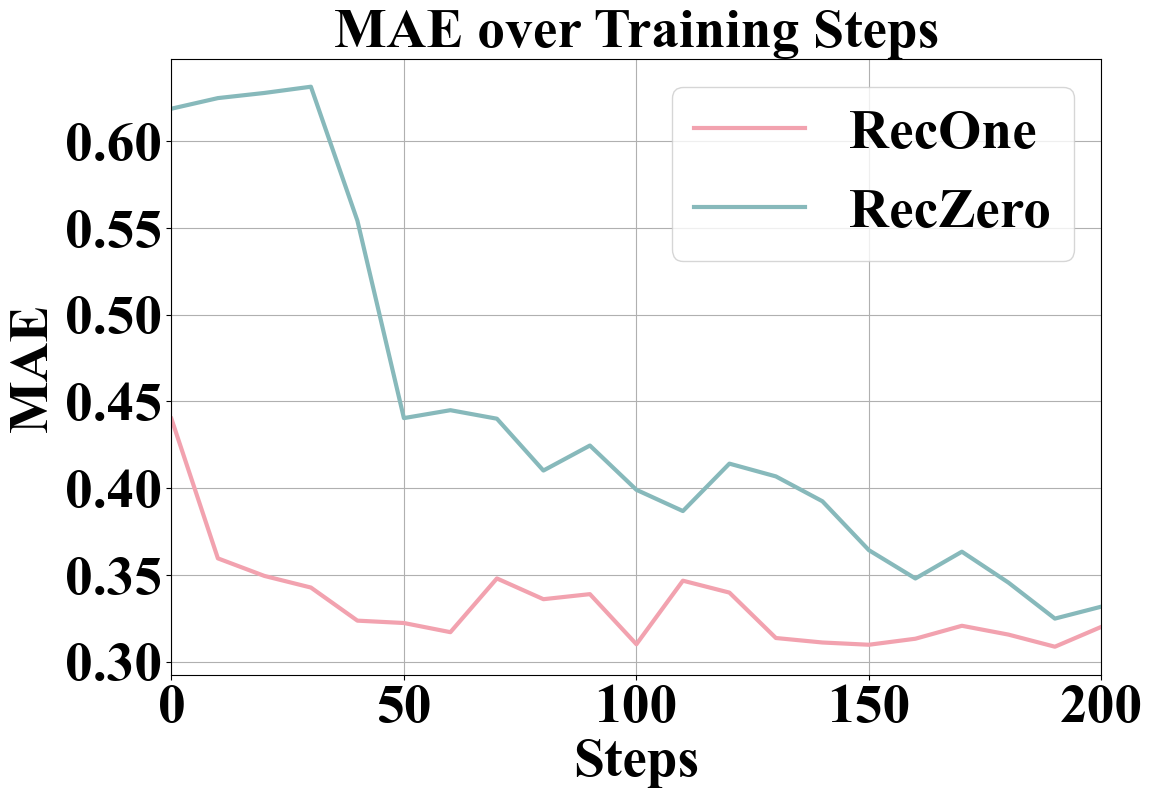
- RecOne reduces RMSE by 12.2% and MAE by 29.9% on the Amazon-Music dataset compared to the best previous baselines.
- On Amazon-Book, RecOne outperforms baselines by lowering RMSE by 6.7% and MAE by 16.8%.
- RecZero (pure RL without teacher initialization) surpasses all baselines in MAE across Amazon-Book, Amazon-Music, and Yelp datasets.
Breakthrough Assessment
8/10
Significantly shifts the paradigm from distillation (imitating teachers) to autonomous RL (learning from results) in RecSys, showing massive empirical gains (up to ~30% MAE reduction).