📝 Paper Summary
Conversational Recommender Systems (CRS)
Data Augmentation
This paper augments CRS training data by using LLMs to identify semantically relevant items often missed as false negatives, then employs a two-stage training strategy to balance this semantic augmentation with collaborative filtering signals.
Core Problem
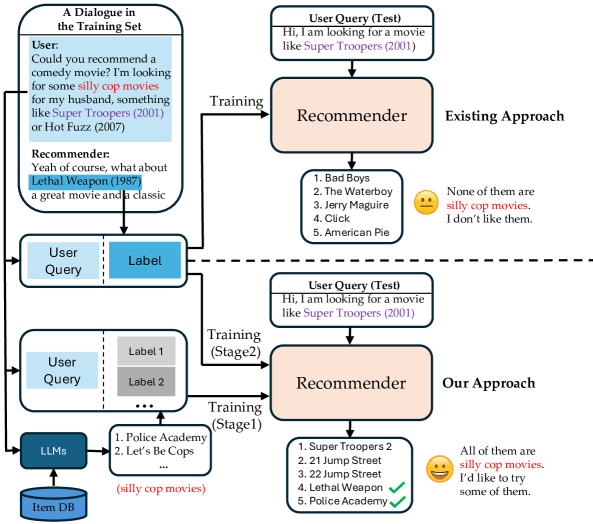
Conversational recommender systems suffer from the 'false negative issue,' where relevant items are incorrectly treated as negative samples during training because the user was never exposed to them.
Why it matters:
- Standard training pairs (query, single recommended item) ignore other valid items the user would like, reducing recommendation quality
- Simply expanding labels with LLMs risks over-prioritizing semantic relevance while ignoring crucial collaborative information (e.g., item popularity, user trends)
- Prior work in traditional recommender systems addresses false negatives, but few approaches exist specifically for the conversational setting
Concrete Example:
If a user asks for 'silly cop movies', the training data might only label one specific movie as positive. The system treats all other silly cop movies as negative (irrelevant), preventing the model from learning to recommend them in future similar contexts.
Key Novelty
Two-Stage Semantic-Collaborative Data Augmentation
- First, use an LLM to retrieve and score multiple semantically relevant items for a dialogue context, ignoring collaborative signals to avoid bias
- Second, train the recommender in two stages: pre-train on these diverse synthetic semantic labels, then fine-tune on the original data to reintegrate collaborative information (like popularity trends)
Architecture
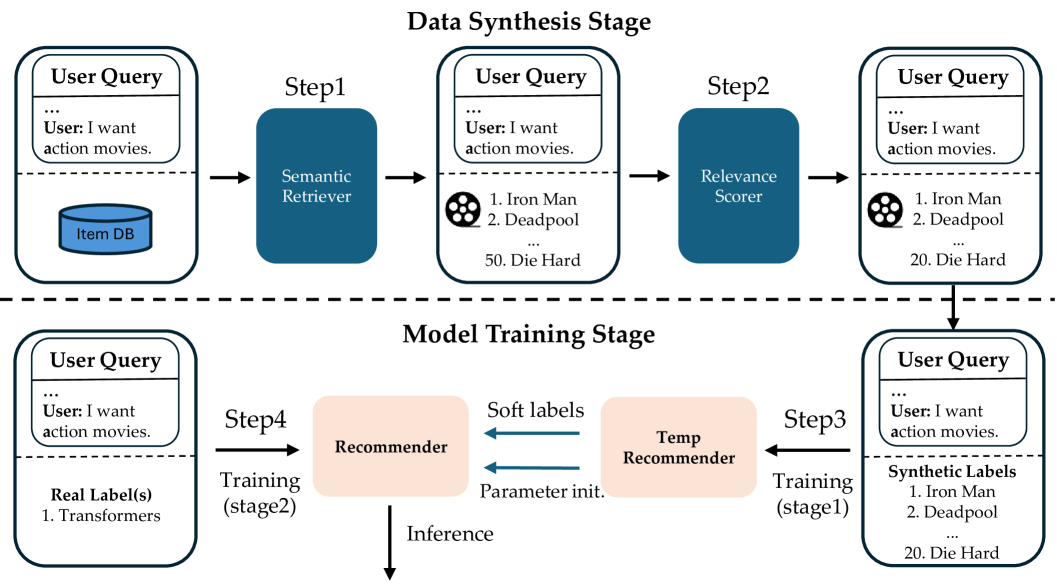
Overview of the proposed approach: Data Synthesis (retrieval + scoring) and Two-Stage Model Training.
Evaluation Highlights
- Outperforms state-of-the-art baselines significantly on ReDial and INSPIRED datasets (e.g., +2.5% to +18.9% relative improvement on Recall@50 for KGSF on ReDial)
- Consistent improvements across multiple base recommender architectures (KGSF, KBRD, UniCRS) and datasets
- Demonstrates robustness in user simulation experiments using iEvaLM
Breakthrough Assessment
7/10
Offers a solid, practical solution to the false negative problem in CRS by effectively balancing LLM semantic knowledge with traditional collaborative signals, showing consistent gains.