📝 Paper Summary
LLM-based Recommendation
Agentic Distillation
Collaborative Filtering
STAR distills the reasoning and tool-use capabilities of a complex multi-agent recommender system into a single efficient model using trajectory-driven fine-tuning and group relative policy optimization.
Core Problem
LLMs excel at semantic reasoning but struggle to perceive latent 'collaborative signals' (behavioral consensus like item co-occurrence) hidden in interaction graphs, while existing agent-based solutions are too slow for real-time inference.
Why it matters:
- LLMs operating only on text descriptions miss the statistical behavioral patterns that drive effective recommendation
- Existing agents that query external data suffer from high latency due to iterative multi-turn generation
- Representation enhancement methods (injecting embeddings) sacrifice the LLM's transparency and reasoning ability
Concrete Example:
When recommending a book, a standard LLM might look at semantic genre matches. However, it fails to see that users who bought 'The Three-Body Problem' also frequently bought 'Dune' (a collaborative signal). A multi-agent system can find this via graph traversal but is too slow to deploy.
Key Novelty
Single-agent Trajectory-Aligned Recommender (STAR)
- Constructs a 'Collaborative Signal Translation' mechanism where a teacher system traverses user-item graphs and explicitly verbalizes behavioral patterns into text evidence
- Uses a trajectory-driven distillation pipeline that serializes the teacher's planning, tool use, and reflection into a linear chain-of-thought
- Aligns the student model using Group Relative Policy Optimization (GRPO) to internalize the logic of *when* to use tools and *how* to self-reflect
Architecture
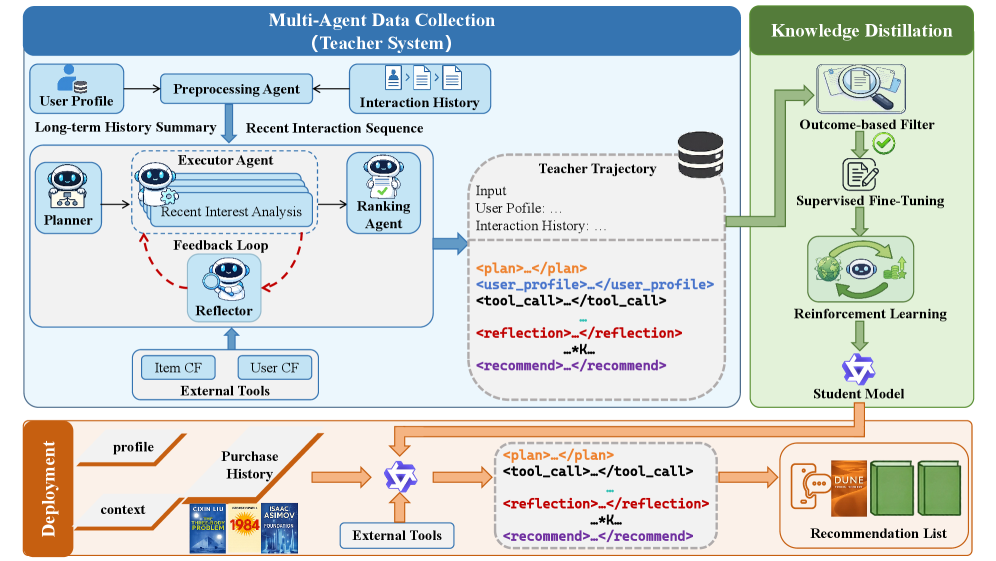
The overall framework showing the transition from the Multi-Agent Recommender System (MARS) to the Single-agent Trajectory-Aligned Recommender (STAR).
Evaluation Highlights
- Surpasses the multi-agent teacher model by 8.7% to 39.5% across various scenarios
- Eliminates iterative latency of multi-turn agent systems by condensing reasoning into a single generation pass
- Successfully internalizes tool-usage syntax and self-reflection logic without needing the actual multi-agent coordination overhead during inference
Breakthrough Assessment
8/10
Strong conceptual contribution in bridging the gap between graph-based collaborative filtering and LLM reasoning via 'translation' and efficient distillation, addressing the critical latency bottleneck of agentic recommendation.